

Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分

2週空いてしまったが再びHot Chips 2024で注目を浴びたオモシロCPUに戻る。第7弾は、MetaのMTIA v2である。初代であるMTIAは連載730回で名前だけ出てきたが、内部についての説明はしていないので、まずはここから話をしたい。
RISC-Vベースだが限りなく専用プロセッサーに近い AI推論用アクセラレーターMTIA v1
MTIA v1は2023年に発表された。目的は推論処理の高速化であり、特に同社のサービスのRecommendation EngineをGPUベースから置き換えることを目的としていた。

製造プロセスはTSMCのN7で、800MHzで動作。INT 8で102.4TOPS、FP16で51.2TFLOPSの性能を持つとされる。

内部構造は下の画像のようになっており、中央に8×8で合計64個のPE(Processor Element)が配される。PEの内部構造そのものは未公開であるが、おのおののPEには2つのRISC-Vベースのコアが搭載され、片方にはVector Engineも搭載されている。
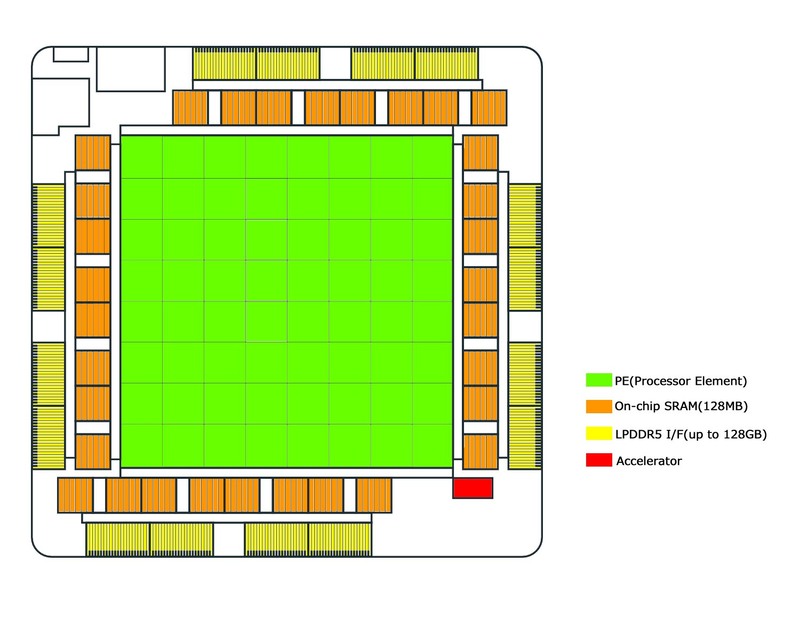
また行列の乗算と加算、データ移動、非線形関数(アクティベーション用と思われる)のための専用命令が追加されているそうで、RISC-Vベースとは言え限りなく専用プロセッサーに近い。おそらくはVector Engineを搭載しているコアには行列の乗加算や非線形関数のアクセラレーターが搭載され、こちらが演算処理を行なう。
もう一方のコアはデータ移動のアクセラレーターが搭載され、これが処理の制御であったり、ほかのPEとのデータ移動だったりをつかさどるものと思われる。64PEでINT 8で102.4TOPSなので、1PEあたり1638.4GOPS。800MHz駆動だから1サイクルあたり2048 Opsという計算になる。
これをVector Engine(つまりSIMD)だけで実装しようとすると巨大なSIMD(16384bit幅!)が必要となるが、どうもこの102.4TOPSは行列乗算(俗に言うTensor Engine)の結果と思われるので、そこまで大規模な回路でなくてもなんとかなりそうだ。これに加え、各PEには128KBのSRAMが搭載されており、スクラッチパッドのように利用可能なものと思われる。
5種類のモデルが存在するMTIA v1
それぞれのPEはメッシュ構成で接続されているそうで、これを踏まえると個々のPEの内部は下図のような構成になっているはずだ。

演算の主体となるRISC-V Core #2は、CPUというよりはDSP的に、ひたすらVector Engineとアクセラレーターをブン回し、演算結果をまたSRAMに戻す格好であろう。1サイクルあたり2KBのデータを読み込んで書きだす格好になるので、128KBなら最大で32サイクル分のデータを格納できることになる。演算前と演算後、両方のデータをSRAMに保持するためだ。実際にはウエイトの分などもあるので、もう少し数は減るだろう。
この演算後のデータをほかのPEに送り出したり、新しいデータを読み込んだりというのはRISC-V #1の方が担当する。おそらくはDMA Engineも持っており、これでメッシュルーターとSRAMの間で直接データ交換ができる(図中の赤の破線のルート)ものと思われる。
ちなみにMetaによればこのプロセッサーはTLP(Thread Level Parallelism)とDLP(Data Level Parallelism)の両方をサポートしているそうで、RISC-Vはどちらもイン・オーダーながらマルチスレッドをサポートしているのかもしれない。
MTIAの内部構造に戻ると、64個のPEを囲むように、32個の4MB SRAMブロックが配されており、合計128MBとなる。その外にはLPDDR5のI/Fが搭載され、容量は最大128GBとされている。上図では16のブロックになっているから、おのおのが16bit幅。実際には容量128Gbitで64bit幅のLLPDDR5チップを4つ接続する形だろうか?
例えばSamsungであれば、128Gbit品がすでに量産に入っており、速度は最大6400Mbpsとされる。これが256bit幅だからメモリー帯域は204.8GB/秒というところで、性能や消費電力を考えれば悪くない帯域と言える。最終的にはデュアルM.2ボードに搭載され、ホストとはPCIe Gen4 x8で接続。消費電力はボード全体で35Wとなっている。

MetaではこのMTIA v1カードをYosemite V3ブレードに装着する。Yosemite V3ブレードはデュアルM.2カードを2枚装着可能だが、MTIA v1カードはブレードあたり1枚に留め、残るデュアルM.2のスロットはPCI Express Switchの接続に利用しているとのこと。
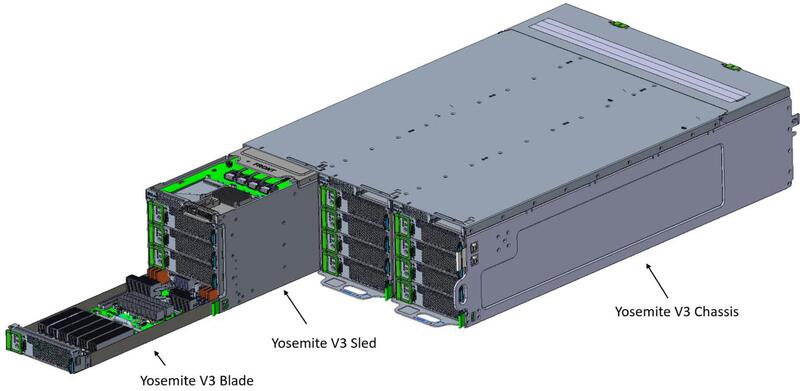
1本のYosemite V3シャーシ(4U)には12枚のYosemite V3ブレードが装着でき、通常1本のラックにはこのシャーシを8本装着するので、ラック1本にMTIA v1が96個搭載される格好だ。なお内部構造の写真右下にあるアクセラレーターは制御専用のユニットで、システム全体のファームウェアが実行され、ホストとの通信やPEへのジョブ制御などをつかさどると説明されている。

冒頭でも少し触れたがMTIA v1はMetaのRecommendation Engineの置き換えを目的としている。もっともRecommendation Engineと一口で言っても、Metaの内部では複数のRecommendationのシステムが利用されている。説明では5種類のDLRM(Deep-Learning Recommendation Model)があり、それぞれの特徴は以下のようになっている。
複雑さというのは、その処理を実効するのにどの程度の能力が必要かの目安で、これが高いほどbatch(推論1回分の処理)に時間がかかる計算だ。
Metaはこの5種類のDLRMを、MTIA v1とNNP-I、それとGPUを利用してそれぞれ実施したそうで、その結果が下の画像である。NNP-Iというのは、インテルが放棄してしまった旧Nervana Systems由来のSprint Hillのことである。どうもMetaはNNP-Iをけっこう導入していたようだ。
結果を見ると、Low complexity 1ではGPUにやや負けているし、High complexityでは半分以下の効率なので、万能ではないものの、Low Complexity 2やMedium ComplexityではGPUやNNP-Iを凌ぎ、一番性能効率が高い結果を得られたとしている。
言うまでもなく昨今のAIをベースにしたサービスのボトルネックは電気代であり、少しでも電力効率が改善されるのであれば長期的には十分採算が合うものになる。万能ではないにせよ、自社のサービス向けには十分役に立つチップとなったわけだ。
MTIA v2で性能は3倍に向上したが チップサイズと消費電力も跳ね上がる
ここから本題のMTIA v2に話を移す。2020年のMTIA v1の設計開始時点から比較すると、Meta社内で利用されているモデルのサイズも複雑さも大幅に増している。

そこでMTIA v2の設計目標は下の画像のように設定された。結果として完成したのがその下の画像だ。


TSMC N5を使いつつ、ダイサイズは421mm2とかなり大規模化している。TDPも90Wまで引き上げられた。おもしろいのは外部接続のメモリーが引き続き128GB LPDDR5-6400になっていることで、帯域は204.8GB/秒のままである。消費電力などの観点から引き上げられなかったのか、それともv1以上の容量/帯域は不要と判断されたのかは不明である。
内部構造そのものは以前と非常に似ている。オンチップSRAMの容量は128MB→256MBに増強された。I/FもPCIe 5.0×8に強化され、またコントローラーもけっこう強力になっている。それとv1では基本的にメッシュネットワーク構成だったのが、v2ではNoCに切り替わった。
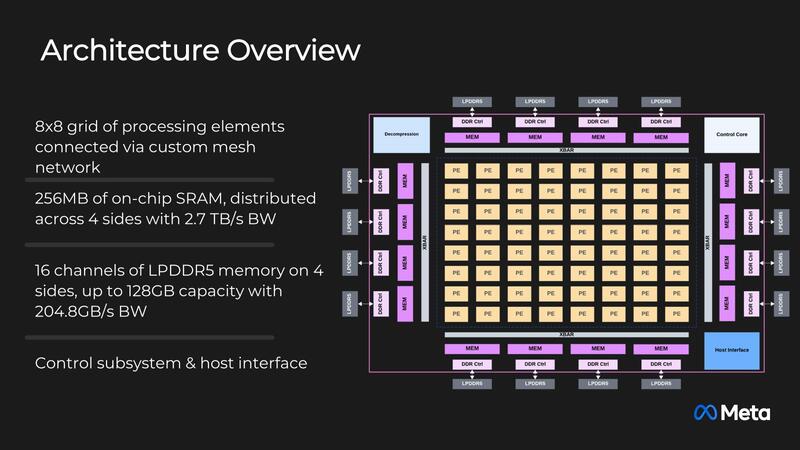


個々のCPの中身が下の画像だ。Vector付きのRISC-VコアとVectorなしのRISC-Vコアが搭載されるのは同じだが、それとは別にコマンドプロセッサーが搭載され(たのか、実はMTIA v1のPEにもあったのかは判断つかないが)、これが行列演算(DPE)や非線形関数(SE)などをまとめて管理する。

スクラッチパッドを384KBに増強 補助電源コネクターが必須に
問題はその性能だ。1.35GHz動作で、PEは64個のままで変わらない。これでGEMM(General Matrix-Matrix Multiplication:汎用行列乗算)が354TOPSとなっているから、1サイクルあたり4096Opsとなる。要するに行列乗算のエンジンの性能が2倍に強化され、それと動作周波数の向上(800MHz→1.35MHzで68.75%の向上)で3.375倍にピーク性能を高めた、という仕組みだ。
その中核である行列演算エンジンの性能は、FP16で2.77TFlops/秒なので、INT 8なら5.54TOps/秒となり、4096 Ops/サイクルでつじつまが合っている。ちなみにPE内部のスクラッチパッドも384KBに増強された。


消費電力がチップあたり90Wまで上がると、さすがにデュアルM.2では収まりきらないようで、アクセラレーターカードはPCIeのフルハイト/フルレングスのものになった。ここに2つのMTIA v2チップを搭載する格好になる。220WではPCIe x16コネクターだけでは電源を供給しきれないので、補助電源コネクターは必須となっている。

当然ここまで大きいと、MTIA v1の時のようにYosemite V3のシャーシには入らない。説明では、2 CPUのシャーシに、片側6枚づつ合計12枚のMTIA v2のカードを装着。このシャーシをラックに3つ搭載する、としている。


2024年前半からこのMTIA v2の展開をスタートしたそうだが、現状はまだMTIA v1とv2が混在している環境の模様だ。それもあって、まだソフトウェアの最適化をしている段階との話だが、7ヵ月目でやっとベースラインに達したレベルでまだ最適化は十分でないようで、性能のベンチマーク結果などは示されていない。

このあたりはもう少しして、最適化が一段落した段階でまたなにかしら示されることになるとは思う。価格あたりの性能や消費電力あたりの性能の改善、Metaのさまざまなサービスへの展開、それと開発の効率化を目指したのがMTIA v2であり、現在はその途中での経過報告といった感じの発表であった。

この記事に関連するニュース
-
AMD、CXL 3.1/PCIe Gen6/LPDDR5に対応するアダプティブSoC「Versal Premium Series Gen 2」を発表
マイナビニュース / 2024年11月13日 6時45分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
新型Macに搭載された「M4チップ」「M4 Proチップ」の実力は? 実機をテストして分かったこと
ITmedia PC USER / 2024年11月7日 23時5分
-
どの「M」が一番速い? Apple Mプロセッサーを今一度整理してみよう(後編)
マイナビニュース / 2024年10月28日 16時4分
-
企業の膨大な内部データを学習可能とした独自大規模言語モデル(LLM)の開発に成功
PR TIMES / 2024年10月24日 13時15分
ランキング
-
1みずほと楽天の資本業務提携で何が変わる? 対面×デジタルの強みを掛け合わせ、モバイル連携は「できない」
ITmedia Mobile / 2024年11月14日 18時30分
-
2「これはひどい」 駐車場は“鳥のマーク”の階→元に戻ると…… “まさかの結末”に絶望 「なんてこった」
ねとらぼ / 2024年11月14日 19時30分
-
3これは合理的だわ!完全ワイヤレスと翻訳機が融合したぞ
&GP / 2020年10月23日 19時0分
-
4Google、Android向けの詐欺とストーカー対策の新リアルタイム機能を追加
ITmedia Mobile / 2024年11月14日 17時59分
-
5「セクシーギャル」ずーっとトレンド入り←『ドラクエ3』の話です! HD-2D版発売日
マグミクス / 2024年11月14日 22時22分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





