

わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分

今回取り上げるのはFuriosaAIのRNGDである。あまり日本では有名ではないが、韓国のファブレス半導体メーカー、要するにスタートアップ企業である。創業は2017年と比較的最近であるが、すでに第2世代製品であるRNGDを完成させ、HotChipsの会場では動作デモを実施したあたりは、製品の発表をしながらちっとも動作サンプルが展示されていないAIプロセッサーベンチャーが多い中では優秀、というべきだろう。
NVIDIAのT4を上回る性能を発揮する 第1世代AIアクセラレーター「Warboy」
第2世代のRNGDの話をする前に、まずは第1世代の製品であるWarboyについて説明したい。実はWarboyが正確にいつリリースされたのかという日付は不明なのだが、2021年9月24日にそのWarboyを搭載した評価基板上でMLPerf 1.1を実施し、NVIDIAのT4を上回る性能を確認したというリリースを出しているので、おそらく2021年中に最初のサンプルは完成しており、量産開始は2022年あたりのはずだ。

ちなみにそのMLPerfであるが、MLPerf Inference:Edge Benchmarkでv1.1を選択すると出てくるが、実はNVIDIA T4に勝ってるか? というと微妙である。この時NVIDIA T4を利用したのはLenovoで、ThinkSystem SE350(CPUはXeon D-2123IT)にNVIDIA T4ボードを装着してMLPerf 1.1 Inferenceを実行した。一方FuriosaAIはCore i9-11900K搭載のシステムに上の画像のボードを搭載したものらしい。
結果は下表の通り。MLPerf 1.1 Inference:Edgeでは3D-UNet-99.0/3D-UNet-99.9/BERT-99.0/ResNet/RNN-T/SSD-Large/SSD-smallの7種類のネットワークが用意され、それぞれオフライン(バッチサイズを1より大きくできる)とSingle Stream((バッチサイズ=1)の2つの方法で実施する。
WarboyはそもそもResNet/SSD-Large/SSD-smallの3種類の結果しか登録していないのだが、いずれのケースでもオフラインではNVIDIA T4の方が高速である(こちらは複数を同時に処理しているから、1秒当たりの処理数で比較)。一方Single Streamの方は、ResNetがT4が0.82msに対してWarboyが0.74ms、SSD-smallが同じく0.47msに対して0.42msと若干ではあるがT4を上回る性能を出しているのは事実である。
ただSSD-Largeでは8.3ms vs 13.62msであり、どのテストでも満遍なくT4より高速というわけではないし、Single StreamはともかくオフラインではほぼT4の半分程度の性能、というのはやはりそれなりに制約があるのがわかる。とはいえ、創業から4年ほどで動作するシリコンの製造にまで漕ぎつけ、それが一部のテストではNVIDIA T4を上回る性能を発揮するというのはスタートアップ企業にとってはうれしいことであったと思う。
FuriosaAIによれば、最初のシリコンが完成して数週間でMLPerfの締切に間に合わすべくデータを取った関係で、上表のデータはソフトウェアの最適化が最小限でのものだったらしい。翌年MLPerf 2.0では下表のように全項目で若干性能が向上しており、特にSSD-smallのオフラインの性能は倍以上になっている。同じMLPerf 2.0 Inference:Edgeに登録されたNVIDIA A2ベースのシステムよりも性能が高くなった、とアピールしている。
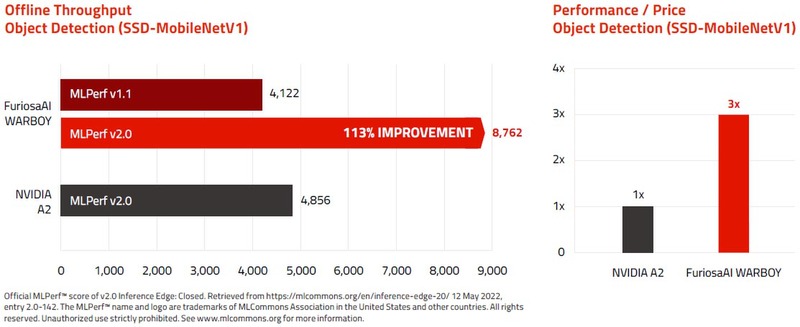
ちなみに最終的な製品はPCIeのFHHL(Full-Height/Half-Length)もしくはHHHL(Full-Height/Half-Length)に収まり、処理性能は64TOPS。オンチップSRAMが32MB、オフチップでLPDDR4X-4266を4つ接続し、16GB(技術的には32GBまで可能)のメモリーを利用可能。TDPは40~60W(Configurable)と説明されている。ホストとはPCIe 4.0 x8で接続される格好だ。
SamsungのチップとSemiFiveのプラットフォームを利用する Made in Korea製品
そのWarboyの内部構造が下の画像だ。制御用にRISC-V(SiFiveのU74)×4を搭載する少しおもしろい構成で、製造はSamsungの14LPPプロセスで行なわれた。実はこのチップ、同じ韓国のSemiFiveが開発したAI inference platformを利用していることが2023年に明らかになっている。
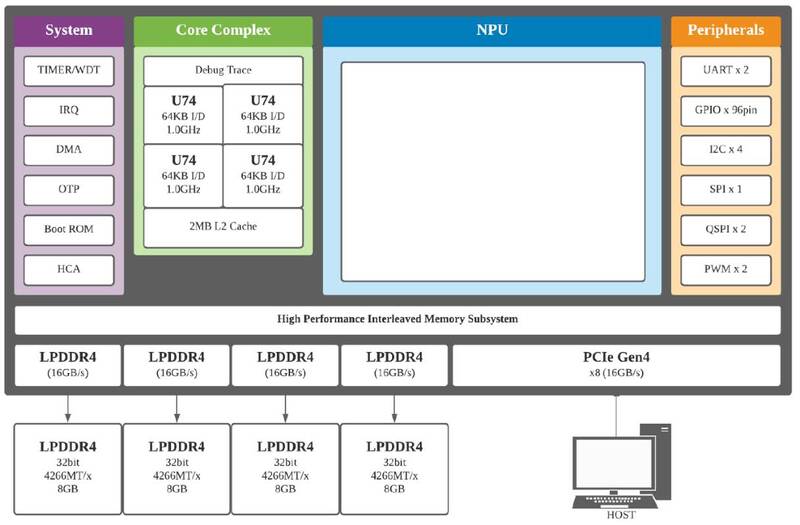
要するに上の画像で、NPUの部分はFuriosaAIが自身で開発したが、その他の部分はSemiFiveのAI inference platformをほぼそのまま利用した格好だ。肝心のNPUの中身は未公開だが、これは次のRNGDのところで触れたい。
WarboyはComputer Vision Processorとしてリリースされた。実際に、16カメラからの同時取り込みと物体認識や超解像/ノイズ削除/圧縮率向上のデモが公開されている。提供はPCIeカードのほか、このカードを複数枚装着したシャーシや、そのシャーシをラックに詰め込んだ形での構成も用意されている模様だ。


HBM3とCoWoS-Sで集積する 第2世代AIアクセラレーター「RNGD」
無事に第1世代の製品展開を済ませた同社が今年のHotChipsで発表したのが第2世代であるRNGDである。発音は"Renegade"だそうだが、そのRenegadeの意味は「反逆者」「背教者」である。Warboyもたいがいではあるのだが、ものすごい名前を付けたものだ。
RNGDは2022年に開発がスタートし、2024年に最初のシリコンが完成という、猛烈なスピードで開発された。

これはまだ開発カードの範疇ではあるのだろうが、限りなく製品に近い構成である。冒頭で説明した8月のHot Chips会場でのデモは、このカードを使って行なわれた模様だ。

構成は、TSMC N5で製造されたチップに12GBのHBM3を2スタック、CoWoS-Sで集積するという最新の構成である。
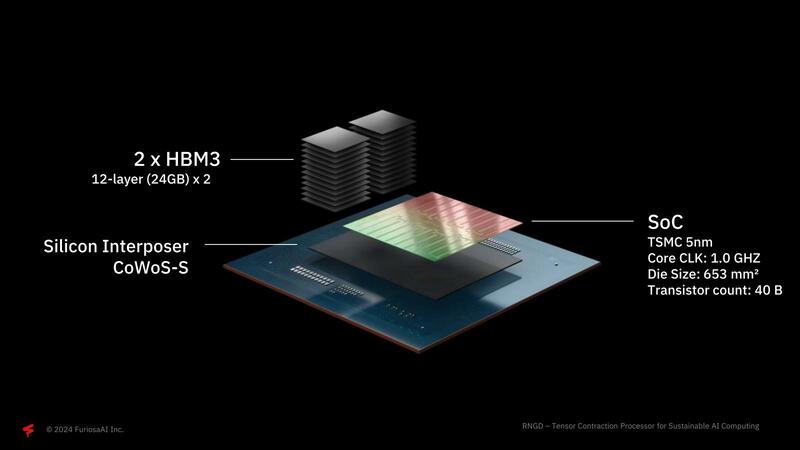
実はこのRNGDでは、SemiFiveのプラットフォームと決別したらしいことが話題になっている。SemiFiveはHPC Platformを高性能プロセッサー向けに提供しているが、こちらはSamsungの5nmをターゲットとし、メモリーはGDDR6ベースである。ところがRNGDはTSMC N5で、しかもHBM3を利用しており、もうこの時点で出来合いのプラットフォームを利用したのではないことがわかる。
またFuriosaAIはArmとFlexible Access for Startupsという契約を結び、初期コストを抑えてArmのCPU IP(今回はCortex-A53を利用している模様だ)を利用していることがArmから公開されているほか、RNGDのPCI Express 5.0 I/FとHBM3のI/FにはRambusのXpressAGENT IPを利用したことをRambusが明らかにしている。
FuriosaAIはRNGDの開発にあたり、デザインパートナーとしてGUCを選択したことが明らかにされている。GUCもAFA(Arm Flexible Access)およびRambusのXpressAGENT IPの利用権を持っており、そしてTSMCの5nmを利用する物理設計が可能な技術力やCoWoS-Sに対応できる能力を持っている。この決断は、「韓国のAIスタートアップが(最初の製品を製造した)Samsung Foundryに見切りを付けてTSMCに鞍替えした」と少し話題になった。
テンソル縮約に特化した内部構造
さて第1世代のWarboyでは公開されなかったNPUの中身である。RNGDではTCP(Tensor Contraction Processor)と呼んでいるが、そもそも畳み込みニューラルネットワークなどでは計算の大半がテンソル縮約(Tensor Contraction)の計算に費やされている。
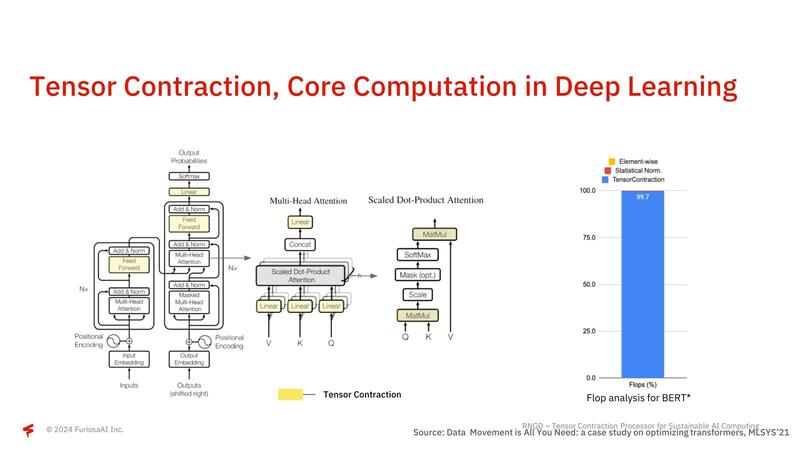
このテンソル縮約は要するに行列積(Matmul)であって、世の中に多く存在するテンソル演算用のアクセラレーター(例えばNVIDIAのGPUに搭載されるTensor Core)はこの行列積を高速に実行するための機構を搭載しているのだが、テンソル縮約≠行列積ではない、とFuriosaAIは主張する。

要するに扱うべき行列のサイズは、大抵の行列積演算ユニットのものよりはるかに大きいので、固定サイズの行列積演算ユニットを使うのは不効率、というわけだ。RNGDはこれをどうしたかというと、行列のサイズに合わせて行列積の計算に使うコンピュートユニットの数をダイナミックに変更しながら、目的のサイズの行列積を一発で行なえる、というところが異なるとする。
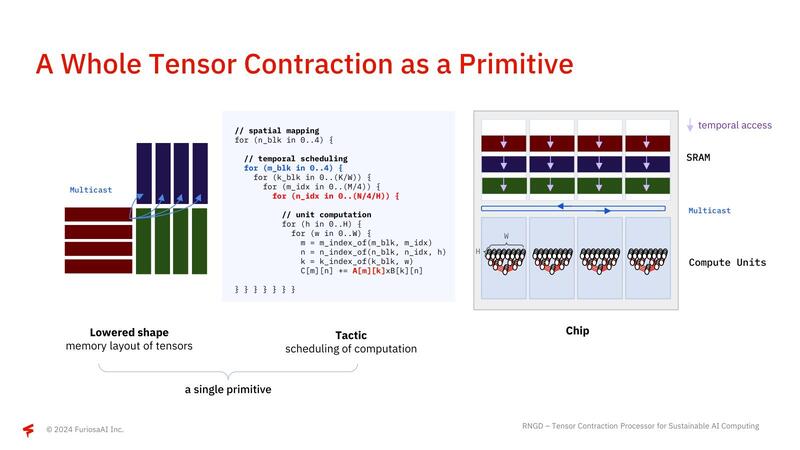
下の画像左側がそのRNGDの構成で、1個あたり64TOPS/32TFlopsの演算性能と32MBのSRAMを搭載するTensor Unitが8つ搭載されている。右側はその個々のTensor Unitの構成で、内部的には8つのプロセッサー・エレメントが配される。
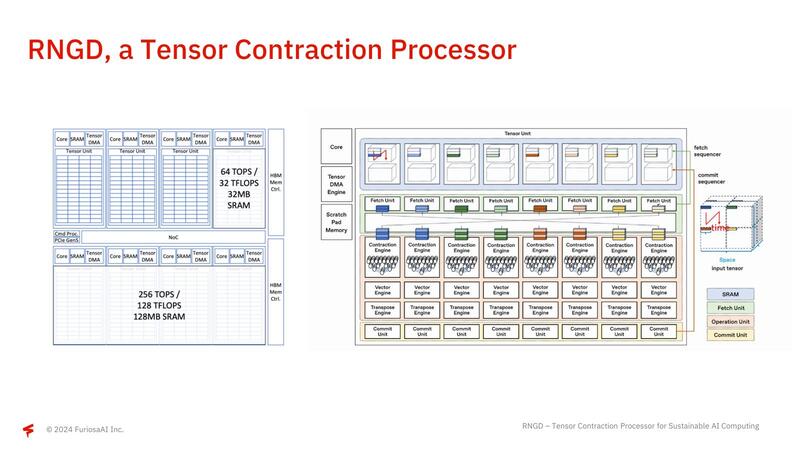
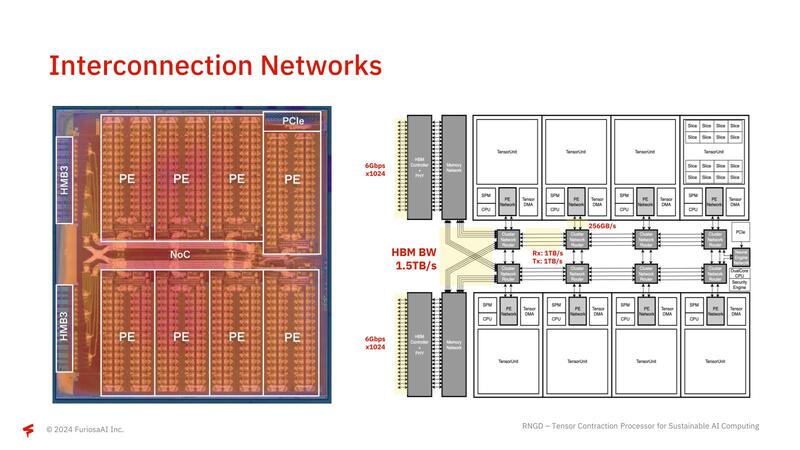
ここでFetch/Commit Sequencerと、テンソル縮約を行うContraction EngineやVector Engine/Transpose Engine/Commit Engineの間にスイッチが入っているのがミソで、大規模な行列に対してすべてのContraction Engine類が協調する形で処理できるようになっている。また個々のTensor Unitの間は非常に高速なNoCでつながっており、HBM3の帯域をすべてのTensor Unitで使い切れるような構成になっている。
性能/消費電力比でNVIDIAのL40Sを60%上回る 2025年には改良モデルのRNGD-SとRNGD-MAXを提供予定
そんなRNGDの性能として公開されているのが下の画像である。絶対性能はともかく性能/消費電力比でNVIDIAのL40Sを60%上回る、としている。

テストはパラメーター60億個のGPT-Jで、こうしたサーバーソリューション向けチップに仕上がっていることを示していると言える。またRGNDは複数カードをPCIe経由で、ホストを介さずに直接接続できるのも特徴である。
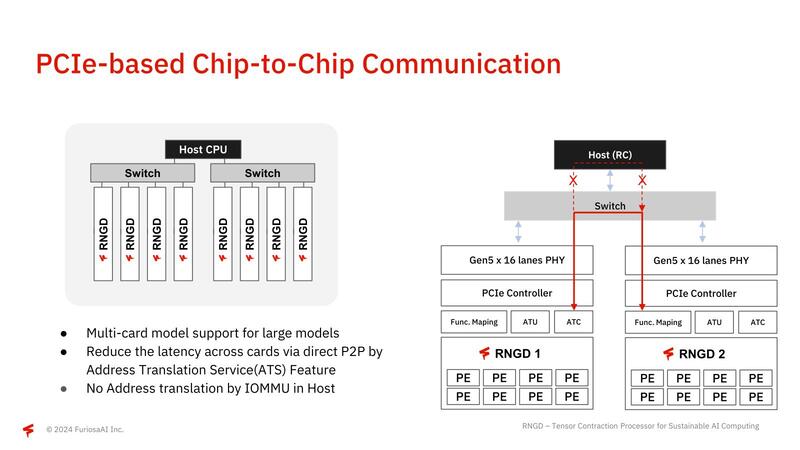
さらにPCIeのI/Oバーチャライゼーションをサポートしているので、例えば1枚のシャーシに複数枚のRNGDを搭載したうえで、PE単位で複数のアプリケーションに割り振るといった動作も可能になっている。
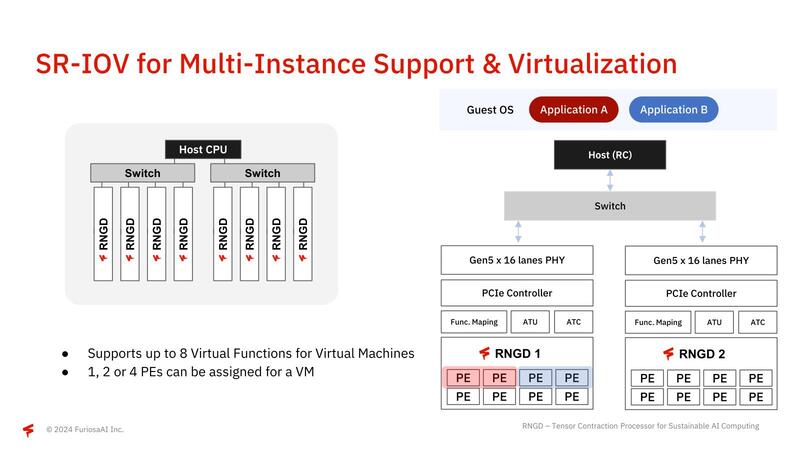
FuriosaAIによれば、今回発表のRNGDをベースに、2025年にはより高い性能になるRNGD-Sと、2チップを搭載したRNGD-MAXを提供予定としている。

RNGDカードは今年第3四半期提供とあるが、現時点ではまだ出荷は始まっていないようだ。とはいえ既にかなり高い完成度を保っているだけに、出荷がそう遅れることはないだろう。

すごく高い競争力を持つというわけではないが、手堅い設計もあってスタートアップ企業とは思えないスピードで製品を市場投入できていることは評価すべきであろう。サーバーと言ってもエッジ向けという感じではあるが、おもしろい製品である。


この記事に関連するニュース
-
HP製パソコンのお得な福袋が登場!セール「新春大祭り」開催!ノートPC、ゲーミングPCなど!年明け前からいち早く開催!ハイスペックなAI PCが最大約43%オフ、約13万円引き!
PR TIMES / 2024年12月26日 11時45分
-
HP製パソコンのお得な福袋が登場!セール「新春大祭り」開催!ノートPC、ゲーミングPCなど!年明け前からいち早く開催!ハイスペックなAI PCが最大約43%オフ、約13万円引き!
@Press / 2024年12月26日 10時0分
-
Thunderboltに無線LAN、10GbE対応の最新デスクトップPC「DAIV FX-I7G7S」を試す
ITmedia PC USER / 2024年12月4日 17時0分
-
SOLUTION∞ Workstationより、マルチGPU搭載モデルを発売
@Press / 2024年12月3日 14時10分
-
ハイエンドスマホ向け新型SoC「Snapdragon 8 Elite」にみるAI半導体の進化
ITmedia PC USER / 2024年11月28日 19時40分
ランキング
-
1三菱UFJ、ネットバンキング障害の原因はDDoS攻撃か
ITmedia NEWS / 2024年12月26日 20時28分
-
2「死ぬほど食べてたやつ」 東京ディズニーランド、6年ぶりに人気フード復活 「やったー!」「本当においしい」歓喜の声あふれる
ねとらぼ / 2024年12月26日 16時20分
-
3「ゲオの初売り 2025」2025年元旦スタート! 中古スマホやゲームなどがお得に
マイナビニュース / 2024年12月25日 15時0分
-
4ソフトバンクから“実質24円/36円スマホ”がほぼ消える、1000~2000倍値上げの機種も ガイドライン改正を受けて
ITmedia Mobile / 2024年12月26日 17時57分
-
5バターを室温に戻す簡単な方法を伝授!老舗洋菓子店主がXで紹介
おたくま経済新聞 / 2024年12月26日 9時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください






