

日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分

Hot Chipsの最後の講演が、Preferred NetworksのMN-Core 2である。Preferred Networksそのものは日本の会社であり、連載670回でも触れたことがある。ASCII.jpでは同社のニュースはいろいろ掲載されているので、ご存じの方もおられるかと思う。

Preferred Networksの西川社長に牧野淳一郎教授から声がかかる
Preferred Networksは2006年創業となるPreferred Infrastructure(PFI)という企業から2014年に独立した企業である。設立当初のニュースを読むと、「IoTにフォーカスしたリアルタイム機械学習技術のビジネス活用を目的とし、自然言語処理技術、機械学習技術分野で事業を行なう」という話になっていた。ところが同社は2017年に神戸大学と共同開発体制を取り、新しいプロセッサーを開発することを決める。
もともとの動機は、理化学研究所とPreferred Networksが2016~2017年に共同で行なったNEDO(新エネルギー・産業技術総合開発機構)向けのプロジェクトである。目的は、行列演算を効率的に実行するためのプロセッサー研究で、TSMCの40nmプロセスを利用して試作した。この時理研で開発の指揮を取っていたのが牧野淳一郎教授であった。2012~2022年に理研の計算科学研究機構 粒子系シミュレータ研究チームのチームリーダーだった人物だ。
Preferred Networksの西川徹社長が、学生時代に牧野教授が手がけていたGRAPE-DRという専用計算機の開発に関わっていたということで、牧野教授から西川氏に声がかかったらしい。プロジェクトそのものは、主にAI推論向けのチップ開発を目指したわけだが、これと並行してAI学習向けのチップを開発するプランが立ち上がることになった。
2017年から牧野教授は神戸大学の大学院理学研究科教授となったことで、この学習向けのチップは神戸大学とPreferred Networksの共同開発になった。
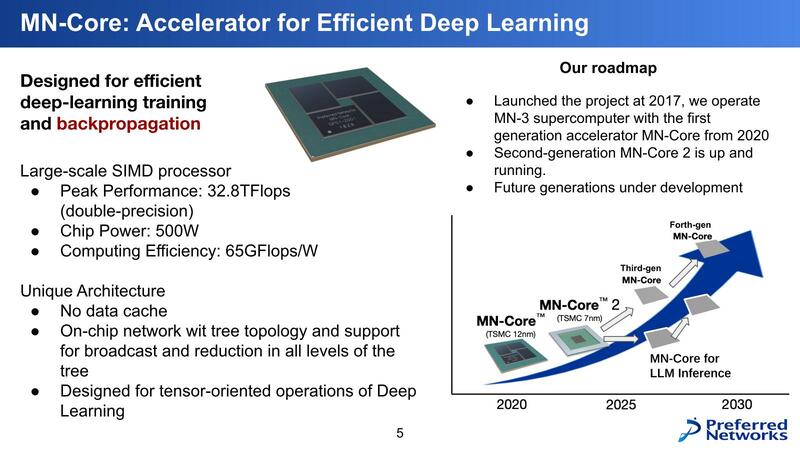
この共同開発の結果として2020年に生まれた最初の製品がMN-Coreであり、これを利用したシステムがMN-3である。製造プロセスはTSMCの12nmで、スペックは、ピーク性能が32.8/131/524TFlops(FP64/FP32/FP16)、TDPが500Wである。

同時代の製品としてはNVIDIA A100がやはり2020年5月の発売であるが、こちらはピーク性能が9.7/19.5/19.5/78TFlops(FP64/FP64 Tensor/FP32/FP16)、TDPが400Wであることを考えると、いかに性能と効率の両面でMN-Coreが高いかがわかるだろう。
先に連載670回に言及したが、MN-Coreを搭載したMN-3は、初参加となる2020年6月のGreen 500で21.108GFlops/Wを達成して見事1位に輝いている。チップ単体の性能で比較すると、FP64の場合でMN-Coreは65.6GFlops/W、A100は24.25GFlops/Wと倍以上も効率がいい。実際にはシステム全体での消費電力での比較なので、こちらで足を引っ張られている感はあるのだが。
なぜそれが可能になったか? それはMN-Coreの特異なハードウェア構造に依存する。このあたりは牧野教授の知見というか経験がものすごく色濃く反映された格好だ。MN-Coreと一般的なプロセッサーの基本的な考え方の違いが下の画像だ。
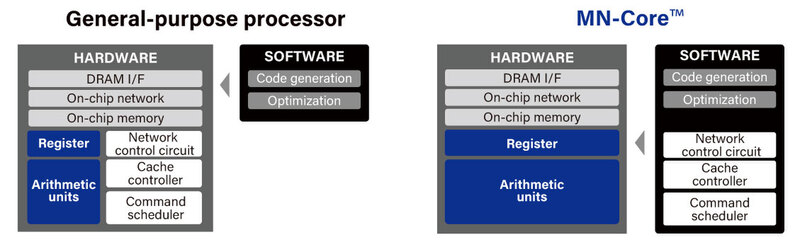
Command scheduler/Cache controller/Network controllerといった実行制御やメモリー制御、複数コアの制御などがすべてソフトウェアで実行されるようになっている。MN-Coreシリーズ(MN-CoreとMN-Core 2の両方)の説明を見ると「従来のプロセッサーとは異なり、アクセラレーター上の各processing element (以下PE)がそれぞれのプログラムカウンターや命令デコーダーを持ちません。すべてのPEは完全に同期的に動作し、ホストCPUで生成された命令列をホストから直接受け取って動作します。」とある。
要するに、連載298回で紹介したQCDSPに採用されたTI TMS320C31や、連載307回で紹介したCM-2に搭載されたWeitek WTL3132など、そういったアクセラレーターに限りなく近い。ただし単純な浮動小数点演算をターゲットにしているのではなく、行列演算をターゲットにしているのが従来との違いというあたりだろうか?
レジスターやメモリーのほとんどがシングルポート ソフトウェア制御だからこそできた珍しい構成
MN-Coreのチップ構造が下の画像である。基本になるのはMAB(Matrix Arithmetic Block)である。こちらはPE(Processing Element)×4とMAU(Matrix Arithmetic Unit)から構成される。
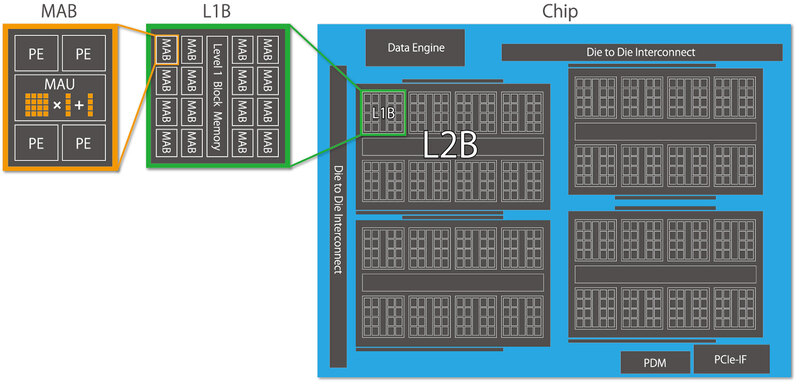
MAUは行列専用のアクセラレーターであり、PEからデータを受け取って行列演算をして、その結果を再びPEに戻す仕組みである。ではPEの中身は? というのがこの下の画像。
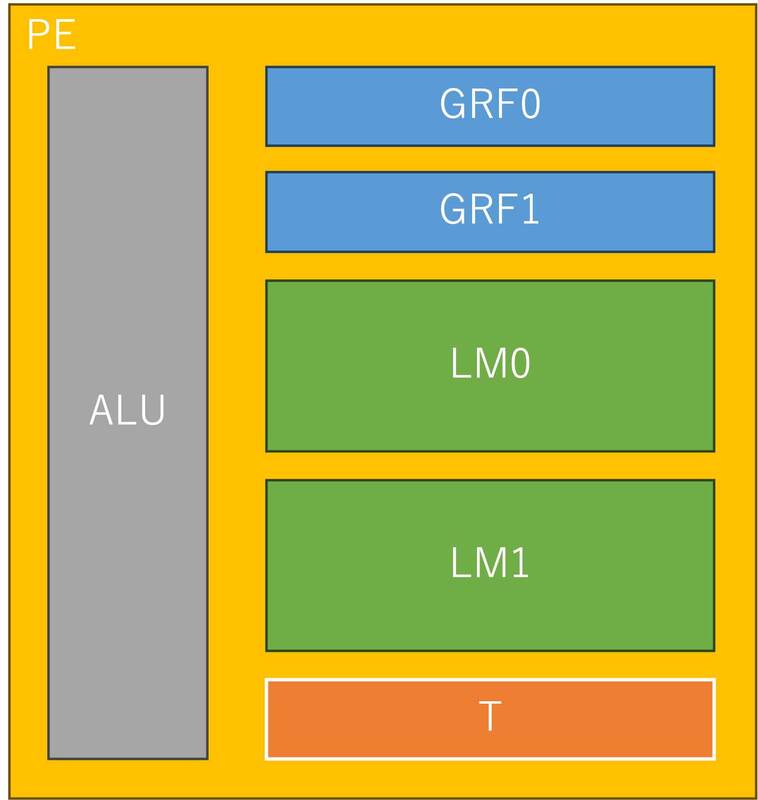
ALUに汎用レジスター(GRF)とローカルメモリー(LM)、それと一時データ保持用のTレジスター、演算結果のフラグを保持するフラグレジスターなども搭載される。LMはそれぞれ36KBの容量を持つが、特徴的なのはこれらのレジスターやメモリーのほとんどがシングルポート構成ということだ。
通常レジスターやキャッシュ、ローカルメモリーはマルチポート構成になっていることが多い。複数のユニットから同時に読み出したり、あるいは書き込みと読み出しを同時に行なったり、といったことが可能な構成になっている。ただこれは当然その分回路が複雑になるし、レイテンシーと消費電力も増える。
MN-CoreではGRF0/1のみR/Wが同時に可能だが、その他のSRAMはすべてシングルポート構成である。これは、通常のコアだとしばしばメモリーアクセスの競合が発生して性能低下の要因になりえるが、MN-Coreの場合はそもそもそうしたメモリーアクセスすらもソフトウェアから制御するので、競合が起きないようにプログラミングすることで無駄なトランジスタ数を減らし、効率を引き上げられる。
ここまででわかるように、PEもMAUも独立して動作する。したがってプログラミング次第であるが、SIMDのようにPEとMAUを並行して同時に動かすことも可能だし、その際の性能予測も容易である。なにしろハードウェア側がなにもしないから、正確に性能を推定できるわけだ。
データ移動も同様にプログラムで管理できるため、きちんとプログラミングできれば非常に効率的に動作する。逆に言えば、プログラミングの難易度は高い。そもそもMN-Core、設計段階でのコード名はGRAPE-PFN2(初代のGRAPE-PFNは冒頭で触れた、NEDO向けの開発プロジェクトのチップの模様)という名前からもわかるように、GRAPEシリーズとかなり似通った命令構成になっている。GRAPEシリーズのプログラミングの経験者であれば、それほど難しくはないという割り切りがあって、こうしたスタイルになったものと考えられる。
NVIDIA A100より高性能で 価格は約半分のMN-Core 2
前置きが長くなったが、ここまでは初代MN-Coreの話で、ここからがHot Chipsで説明のあったMN-Core 2の話である。下の画像が初代MN-Coreのまとめであるが、MN-Core 2の次には推論向けと学習向けで異なるラインナップを用意するという話が出ている。
第2世代のMN-Core 2であるが、目標は高い性能/消費電力比を維持しながらコストを下げることにあるとする。
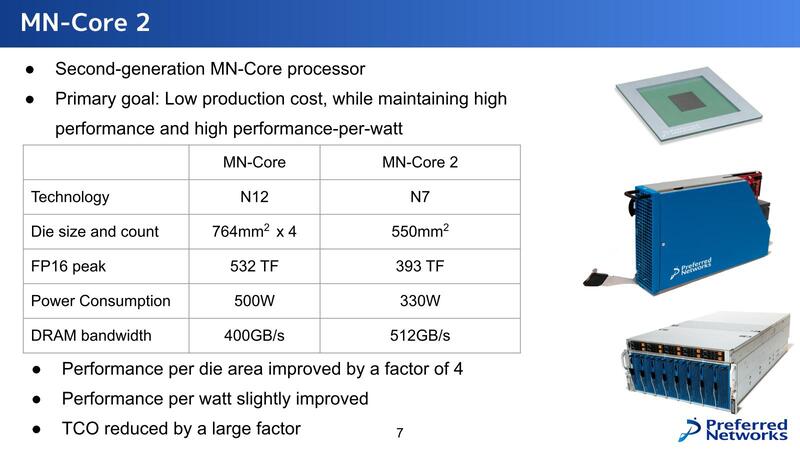
MN-CoreとMN-Core 2の違いは下の画像のとおりで、MN-Core2ではダイあたりのL2Bの数が8つに増えている。とはいえMN-Coreでは4ダイで16個だったから演算器そのもので言えば半減である。

しかしMN-Coreでは500MHz駆動だったのが、MN-Core 2では750MHzと1.5倍になっている関係で、性能はMN-Coreの75%ほどに落ち着いている。実際性能が393TFlops vs 532TFlopsで73.9%ほどに収束しているから、ほぼ計算通りと言える。
細かいところでは、例えばメモリーの搭載量は半減しているが、演算器の数も半分なので実質変わりはないし、むしろLPDDR4→GDDR6Xで高速化されているから、メモリーアクセスのレイテンシーを減らせて性能を上げやすくなっているともいえる。
性能として示されたものが下の画像である。アプリケーションによって差の開き方がだいぶ変わるのだが、ResNet-50の学習で2倍、推論で4倍というのはわりと大きな差だし、姫野ベンチマークでは14倍以上の差がついているのがわかる。姫野ベンチマークについては理研のウェブサイトを参照してもらいたい。メモリー依存度が非常に高いベンチマークである。
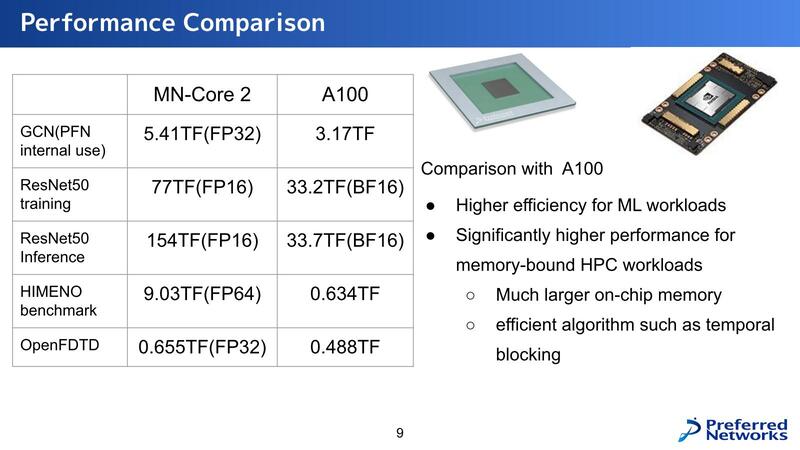
問題はLLMに利用するにはあまりにメモリーが足りなさすぎることだ。今年9月にCloud Operator Days 2024というイベントがあり、そのクロージングでPreferred Networksが「自社開発した大規模言語モデルをどうプロダクションに乗せて運用していくか~インフラ編~」という発表をしているのだが、この中でモデルが巨大すぎ、かつCUDAが必須なので現実問題としてNVIDIAのGPUを使うしかなく、しかもH100/H200は全然入手できないのでA100の利用が現実的、という話をされている。
その意味ではMN-Core 2の性能をA100と比較するのは間違っていないのかもしれない。ただ現実問題として16GBのMN-Core 2では大規模LLMが乗り切らないので、ホストメモリーを併用することになるが、こんなことをしたらまともに性能が出るはずもない。
またCUDAで書かれたコードをMN-Core向けに書き直すのも猛烈に大変である。したがって、今のところMN-Core 2をLLMに使うという話が見あたらないのが、現時点での最大の問題かもしれない。
などと考えていたら、11月15日にPreferred NetworksよりMN-Core L1000の開発に関する発表があった。DRAMをチップの上に3次元実装することで、LLMに必要となる大量のメモリーをHBMよりも安価かつ高速に実現できる、という目論見だそうだ。登場時期は2026年の予定となっている。

話を戻すと、すでにMN-Core 2は発売されており、MN-Core 2を8枚搭載するMN-Server 2 V1が2000万円、1枚搭載のMN-Core 2 Devkitが200万円となっている。おそらくMN-Core 2のカード単価で言えば150万~160万円程度。昨今の為替レートを考えると1万ドル前後というあたりで、ラフに言ってA100の半額、インテルのGAUDI 2よりややお高めといったところだろう。

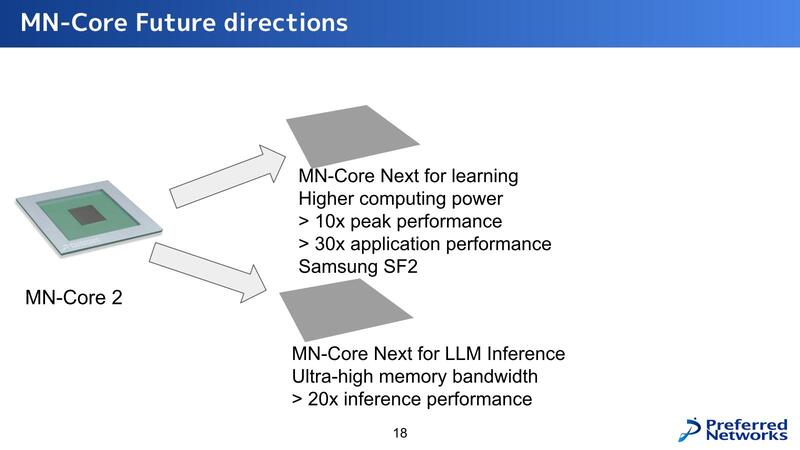
次世代製品については、学習向けではピーク性能10倍とアプリケーション性能30倍、推論向けは性能20倍としている。それはいいのだが、学習向けがSamsungのSF2というあたりに一抹の不安を覚えざるを得ない。ちゃんと製品が作れるのだろうか?

この記事に関連するニュース
-
法人向け生成AIプラットフォームAskDona、Claude 3.5 Haikuに対応!
PR TIMES / 2024年11月13日 12時40分
-
MCデジタル・リアルティのNRT12データセンターが、Preferred Networks のAI計算基盤に採用
PR TIMES / 2024年11月12日 15時15分
-
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月11日 12時0分
-
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月4日 12時0分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1スマホで“理想の部屋”を再現できる! LOWYA公式のインテリア再現アプリ「おくROOM」が「楽しすぎんだろ!!」「ありがたい」と話題
ねとらぼ / 2024年11月18日 7時10分
-
2アップル新型「Mac mini」押しづらい電源ボタンの解決策、ガチで登場へ
ASCII.jp / 2024年11月18日 11時15分
-
3発熱する「iPhone 12 mini」のバッテリー、よく見ると膨張……街中の修理店で交換した結果は?
ITmedia Mobile / 2024年11月17日 10時5分
-
4HD-2D版『ドラクエ3』パッケージが転売ヤーの餌食に?「どこにも売ってない…」
マグミクス / 2024年11月18日 11時45分
-
5オウム、飼い主困惑の“とんでもねえ特技”を披露する 支払い明細が心配な光景に「恐怖ですね」「手慣れてるwww」
ねとらぼ / 2024年11月18日 8時30分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





