

世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
ASCII.jp / 2024年11月25日 12時0分

11月17日からアトランタでSC24が開催され、11月18日にはTOP500の2024年11月版が公開された。予想通りではあるが、AMDとHPがローレンス・リバモア国立研究所に納入したEl Capitanが大幅に性能を更新、堂々1位を獲得した。以下10位までは下の画像のとおり。このEl Capitanの構成をもう少し見てみたい。
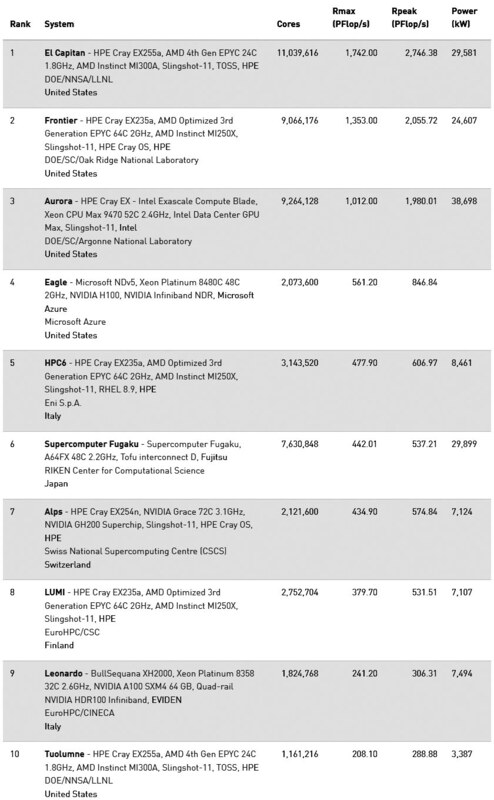
AMDとHPが共同開発したスパコンEl Capitan
El Capitanは、計算部はInstinct MI300Aのみで構成されるシステムである。コア数は1103万9616個で、うちAccelerator/Co-Processorは998万8224個とされる。つまりCPUコアは105万1392個であり、Instinct MI300Aは1個あたり24コアのZen 4が搭載されるため、Instinct MI300Aの数は4万3808個という計算になる。
逆にAccelerator/Co-Processorの数を4万3808で割ると、Instinct MI300A 1個あたり228コアという計算になる。これは連載751回で説明した個数と同じである。

さてEl Capitanのノード構成だが、2023年8月23日付の"El Capitan: The First NNSA Exascale System"というスライドを見ると、連載726回で紹介したように、4つのGPU+1つのCPUから構成されるという説明があるのだが、このRabbit-4Uは"Deployed in LLNL EAS3s"(すでにEAS3sに展開済である)という記載がみられる。
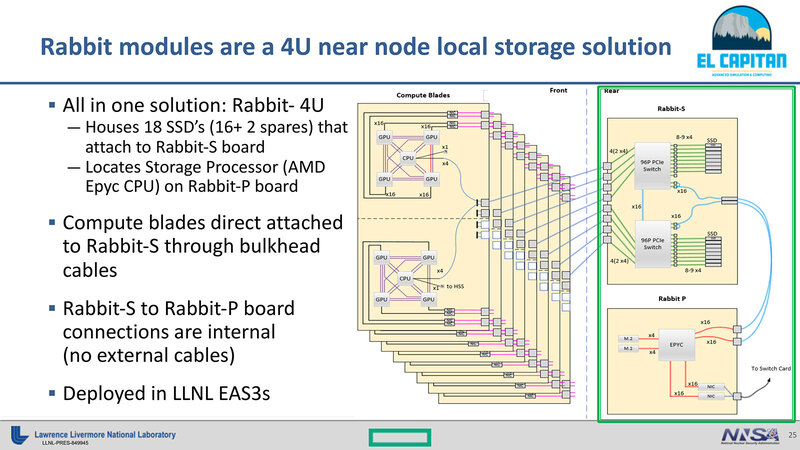
EAS3sとはなにか? を調べたら、ECP(Exascale Computing Project)のインタビュー記事の中に「我々のEAS3(第3世代のアーリーアクセスシステム)は、Frontierと非常に類似したシステムです。MI250X GPUとTrento CPUを搭載しており、(ソフトウェアから見ると)ほぼ同一のシステムです。各ノードにSSDは搭載されていませんが、代わりにRabbitsを導入し、El Capitanでの使用に備えています。AMD GPUの使用準備は、当社のチームにとって非常に容易な作業でした。その結果、El Capitanで(ソフトウェアが)すぐ利用可能になります」という記述があった。
つまりこのGPU×4+CPUの構成はあくまでもEAS3sのものであり、本番のEl CapitanはこれをMI300A×4で置き換えている可能性が非常に高い。具体的には下の画像のとおりであろう。つまり4つのInstinct MI300Aで1つのノードを構成。2ノードで1枚のCompute Bladeを構成する格好だ。だとするとブレード1枚で8個のMI300Aが搭載されるので、ノード数は10952、ブレード数は5476枚となる。
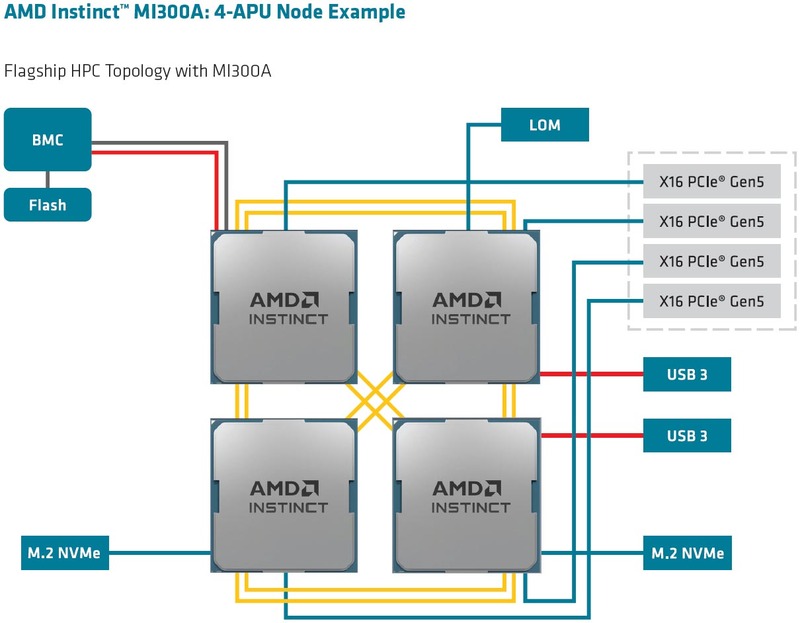
連載726回の推定ではRmaxが2EFlops程度を推定して4000ノード/2000ブレードという数字を出したが、実際にはこれを超える2.7EFlopsの構成だったこともあり、大幅にノード数が増えることになってしまった。
次に動作周波数について。Instinct MI300Aは定格ではCPUが3.7GHz駆動、GPUが2.1GHz駆動となっており、FP64での性能はGPUが61.3TFlops、CPUが1420.8GFlopsとなる(AVX512で積和演算を行なうとすると、1サイクルあたり16Flopsになることから計算)。合算すると62.7208TFlopsである。
丸めて62.72TFlopsとして、これが4万3808個なのでトータルで2747.638PFlopsという計算になり、これはEl CapitanにRpeak(理論ピーク性能)として登録された2746.380PFlopsにかなり近い。つまり最大動作周波数はほぼ定格のままで運用されているものと考えられる。
消費電力についても検証しよう。Instinct MI300AのTDPは液冷で760W、空・液冷で550Wということになっている。仮に液冷での数字である760Wを採用すると、ノードあたり3040W。ブレード1枚だと6080W。実際にはイーサネットのPHYや、その他管理用の周辺回路などもあるだろうから、とりあえず6100Wとしておく。
これが5476枚だと、それだけで3万3403.6KWになる。システム全体だと5万KWを超えかねない数字であるが、実際に登録された数字は2万9581KWである。TDPを550Wとするとノードあたり2200W、ブレード1枚で4400W。少し上乗せして4500Wとして、5476ブレードで2万4642KW。ストレージやネットワークスイッチ、冷却装置の分まで加味すると、これでもかなり厳しい。
したがって、実際にはInstinct MI300A 1つあたり450~480W程度まで落とすように調整して運用している、と考えるのが妥当かと思われる。定格動作周波数を下げるのではなく、消費電力枠をこの450~480Wに設定して、動的に動作周波数の制限をしているのだろう。
効率の方はRpeak 2746.38PFlopsに対し、Rmax 1742.00PFlopsで63.4%ほど。ただ2位になったFlontierの方もRpeak 2055.72PFlops/Rmax 1353.00PFlopsで65.8%なので、初回の成績としては悪くないという見方ができるだろう。
大規模システムは性能を上げると効率が落ちるが 小規模システムなら性能と効率のどちらも上げられる
TOP500の2024年11月版で10位となったTuolumne、これもローレンス・リバモア国立研究所のシステムである。El Capitanは、実はサイエンス向けというよりも核実験シミュレーション(連載286回で説明した、ASCI/ASCの流れを汲む用途)がメインである。そこで、より小規模なサイエンス向けのシステムとして、El Capitanとは別に提供されるのがTuolumneであり、2021年に初めてその計画が明らかになった。
こちらはRpeakが288.88PFlopsで、El Capitanのほぼ10分の1のサイズである。実際総コア数は116万1216、うちAccelerator/Co-Processorが105万624で、CPUコアは11万592。つまりInstinct MI300Aが4608個、ノード数1152/ブレード数576枚とかなり小規模である。このTuolumneでの効率は72.0%とずっと高くなっているあたりは、小規模なゆえにネットワークのレイテンシーもずっと少ないのが効率の向上につながっていると思われる。
おそらくEl CapitanとTuolumneではバックボーンの規模が違う。ベースとなるのはどちらも681回で紹介しているDragonFlyであるが、下の画像の例では、8ノードからなる小さなクラスター同士を相互接続する、いわば2段構造である。
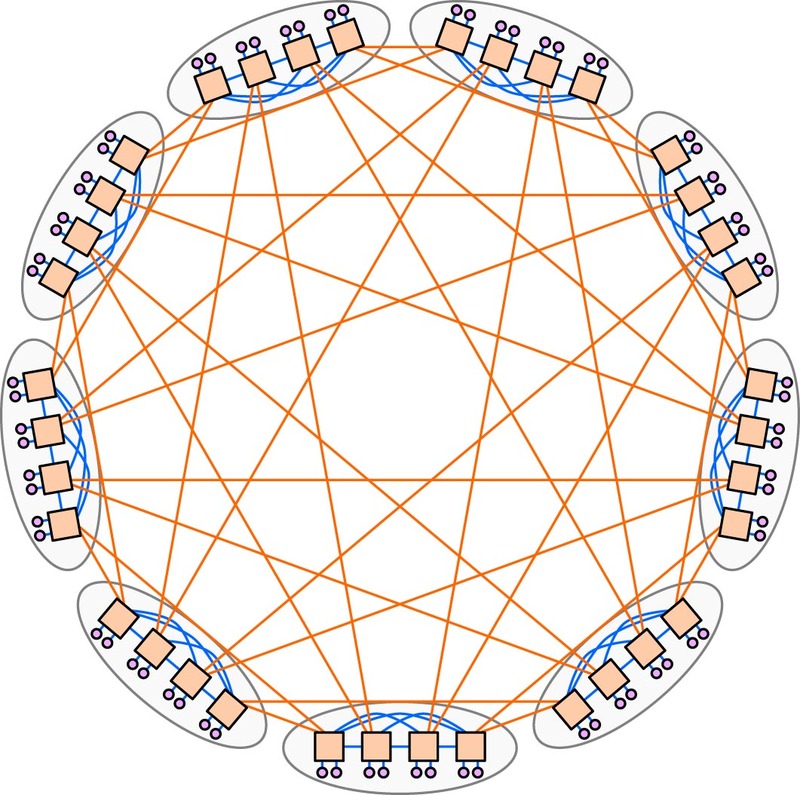
Tuolumneでは、クラスターそのものが16ノード程度になり(これを小クラスターとする)、この小クラスターを8つ相互接続した中クラスターを9つまとめた大クラスターでシステム全体を構成するという、3段構造あたりが考えられる。
そしてEl Capitanではその大クラスターを10個ほど集めて相互接続する巨大クラスター構成あたりになりそうだ。要するに、4段構造になると想定される。この段数の差がレイテンシーの差につながり、効率の低下をもたらすというあたりが正直なところではないかと思う。
性能/消費電力比は58.89GFlops/Wで、今回のGreen 500では18位にランキングされている。とはいえ、Frontierの54.98GFlops/W(ランキング22位)よりは良い結果である。ローレンス・リバモア国立研究所はEl CapitanやTuolumne(12位)以外にrzAdams(10位 )をInstinct MI300Aベースで立ち上げており、他にサンディア国立研究所がEl Dorado(13位)をランクインさせている。
またフランスGENCI-CINESのAdastra 2はやはりInstinct MI300Aベースながら69.10GFlops/Wでランキング3位に輝いている。このAdastra 2、Rmax/Rpeak比は79.9%と極めて効率も高い。ただしInstinct MI300の数は64個。ノードで言えば16である。要するに小規模なシステムであれば、性能効率と消費電力効率のどちらも上げるのは極めて容易という話であって、問題は大規模にスケールさせると途端に悪化することである。
下のグラフは、今年のGreen 500のリストからTop 199を選んで、Rmaxの値とEnergy Efficiencyでプロットしたものである。なぜGreen 500から選んだかというと、今回リストに入った500システムのうち、消費電力を申告しているのは199システムしかなく、それがGreen 500の199位までにランクインしているからである。
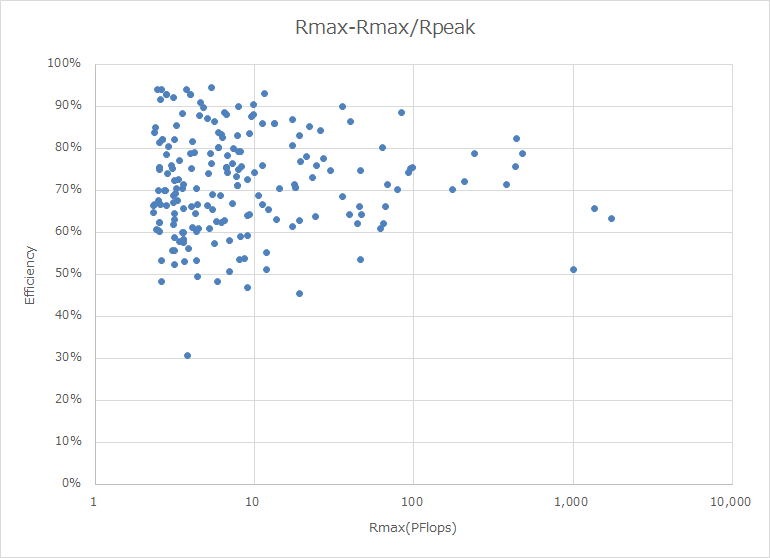
実際に見てみるとRmaxが1~10PFlops程度のシステムでも大多数は30GFlops/W未満で、そもそも30GFlops/Wを超えるシステムは少ないのだが、60GFlops/Wを超えるような高効率なシステムはRmaxが100PFlops以下に集中しており、これを超えるのは本当にごくわずか、ということだ。
要するに絶対性能を上げると効率はどうしても落ちる。こうしてみると、Auroraですらこの性能で30GFlops/W弱を維持できているのは素晴らしいともいえる。もっと上のEl Capitan/Frontierと比べてしまうと見劣りはするが。
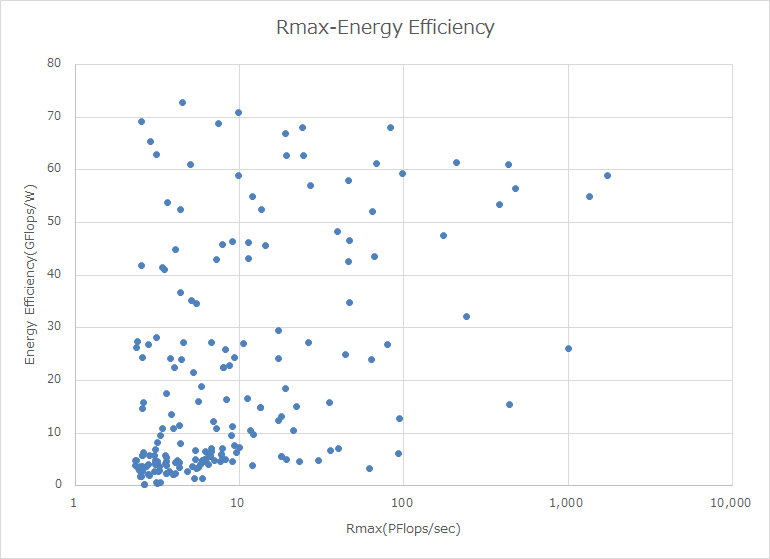
下のグラフは同様に、縦軸を性能効率(Rmax/Rpeak)、横軸をRmaxとしてプロットしたもので、10PFlopsくらいのマシンであれば効率90%以上も期待できるが、100PFlopsでは最大でも80%、1000PFlopsだと70%程度で、これを超えると60%に落ちている。当然と言えば当然の結果ではあるのだが、ピーク性能を求めるとどうしても効率が落ちるのは避けられない、という話が再確認できた格好である。
NVIDIAのBlackwellはHPC向けの性能はあまり期待できないので、あとはAMDがInstinct MI350/400世代のHPC向けでどの程度性能を引き上げられるか、あるいはインテルのFalcon Shoreがどの程度の性能なのか、というあたりが次の話題になりそうだ。
ちなみに今回のSC24で、インテルは恒例だったHPC製品のロードマップ公開を止めた模様だ(まだ原稿執筆時点でSC24は終わっていないので、この後行なわれる可能性はあるが、インテルのウェブサイトを見ている限りなさそうである)。Falcon Shoreの進捗とか知りたかったのだが、残念である。
マイクロソフトとAMDがAzure HBv5を発表 HBM3を搭載したInstinct MI300CなるものをMSが特注
SC24と並行して11月19日からMicrosoft Igniteもスタートした。基調講演の様子はYoutube視聴できるが、ここでマイクロソフトはAMDと協業する形で、Azure HBv5を2025年から提供開始することを発表した。

マイクロソフトの説明によれば、「カスタム Advanced Micro Devices(AMD)EPYC 9V64Hプロセッサーを搭載し、Azureでのみ利用可能です」「これらの性能向上は、高帯域幅メモリー(HBM)と高性能Zen4コアを使用して、これまでで最もスケーラブルなAMD EPYCプロセッサー・プラットフォームと、最新のNVIDIA InfiniBandネットワーキング・テクノロジーを構築しています」といった説明がされている。
上の画像から見てわかるように、これはMI300A/MI300Xとまったく同じパッケージを利用している。同日公開されたAzure HPC Blogのエントリーによれば、以下の特徴が述べられている。
- HBMを利用し、6.9TB/秒のメモリー帯域と400~450GBのRAM容量を利用できる
- トータルで352のZen4コアを搭載
- SMTは無効化
またSC24のAzureのブースで、HBv5用のシステムを展示しているという説明があった。

さてこれはなにか? という話だが、実は昨年8月くらいにInstinct MI300Cなる噂が流れたことがあった。つまり、MI300Aは6 XCD+3 CCD、MI300Cは12 XCD、MI300Xは8 XCDである。
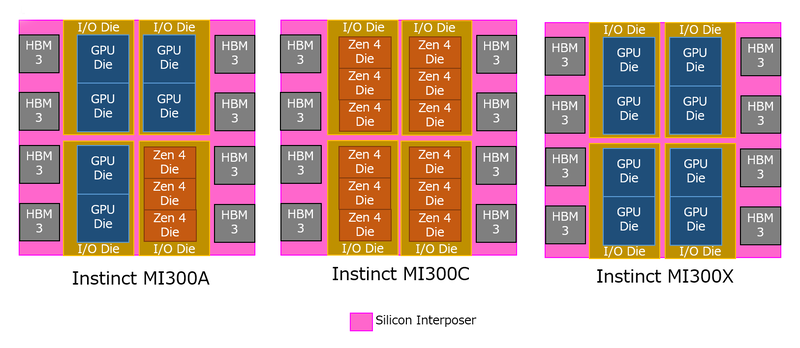
技術的には簡単で、インターポーザーとI/Oダイ、HBM3には違いはなく、単にI/Oダイの上にXCDを載せるかCCDを載せるかであり(I/Oダイはどちらを載せることも可能だが、混載はできない)、あとはやるかやらないかだけの話である。
今回はカスタムEPYCだ、と明確に言っていることからわかるように汎用品ではなく、マイクロソフトの求めに応じる形でAMDがInstinct MI300CをEPYC 9V64Hという名称でリリースしたようだ。
なお、EPYC 9V64H×4で352コアなので、EPYC 9V64Hが1つあたり88コアという計算になる。一方Zen 4 CCD×12なら96コアなので、おそらく実際には96コア構成で、ただしVMとしてAzureのユーザーに提供するのはうち88コア、残り8コアはシステム管理用あるいは冗長用としてリザーブというあたりであろう。
HBM周りがInstinct MI300Aと変わらないとすれば、容量は128GBでメモリー帯域は5.3TB/秒なので、微妙に数字が合わないが、Blogのエントリーによれば最大でコアあたり9GBほどのメモリーが利用可能とあるので、88×9=792GB、管理用の領域まで考えると800GBくらいになり、HBMが1スタックあたり100GBとなって、「そんなHBMはない」という話になる。
可能性だが、下の画像のようなEPYC 9V64H×4の構成で、おのおののCCDあたり動かすコアを1コアに限ったとすれば、128GBのHBM3を11コアで占有できるのでコアあたり11GB強。実際にはシステム管理用などの予約領域もあるから、11GBをフルに占有は無理で9GBというあたりな気がする。これは特にメモリー容量が効くタイプのアプリケーションではありえる話で、実際そういう構成だとコアあたり32MBのL3を占有できるのも大きい。
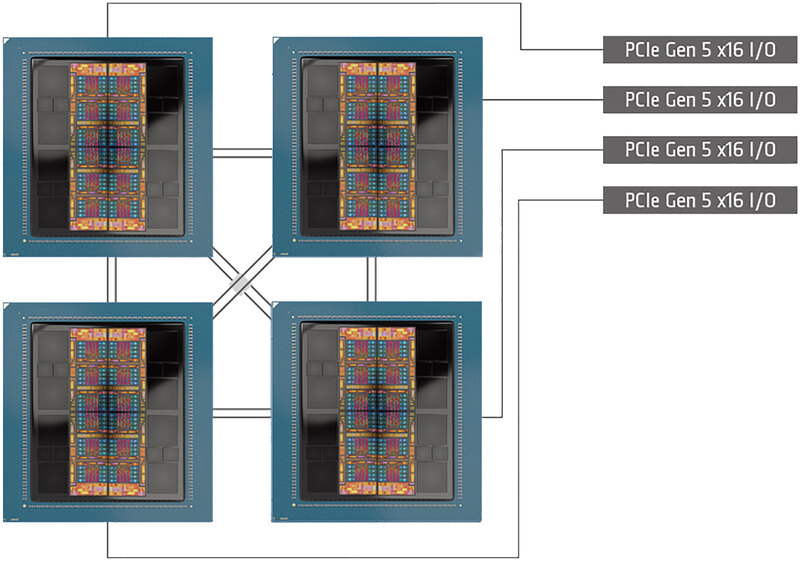
またメモリー帯域が6.9TB/秒というのも少し怪しい。というのは連載795回で説明したように、HBM3Eの速度を5.86Gbpsに引き上げたInstinct MI325Xですらトータルで6TB/秒であり、普通に6.9TB/秒を実現しようとすると信号速度は6.74Gbpsまで引き上げないといけない。現実問題これが可能か? というとかなり厳しいからだ。
実はこの6.9TB/秒というのはSTREAMのTriadベンチマークの結果だが、インフィニティ・キャッシュが効いているのではないかという気がしてならない。ブログの説明では"6.9 TB/s of memory bandwidth (STREAM Triad) across 400-450 GB of RAM (HBM3)"とあるのだが、インフィニティ・キャッシュが効いている範囲は最大17.2TB/秒の性能が出る。
ただしインフィニティ・キャッシュはIODあたり64MBなので、これを超えるとガクンと性能が落ちるが、それでも均すと6.9TB/秒になる、というあたりが正確なところだろう。いずれマイクロソフトがAzure HBv5の詳細な性能を公開すると思うので、そのあたりまでのお楽しみにしておきたい。
EPYC 9V64Hは、インテルのXeon MAXシリーズに比肩しうる構成である。今はカスタム版扱いでマイクロソフトのみに提供しているが、HPC向けにニーズがあれば標準製品に昇格する可能性もあるだろう。

この記事に関連するニュース
-
Supermicro(スーパーマイクロ)、液冷NVIDIA Blackwell ソリューションを提供
共同通信PRワイヤー / 2024年11月22日 15時8分
-
IBM、AMDとのさらなる協業を発表。AIアクセラレーターの提供を拡大
PR TIMES / 2024年11月21日 16時45分
-
HPE、直接液冷スーパーコンピューティング ソリューションの展開を拡大、同時にサービスプロバイダーおよび大企業向けAIシステム2機種を発表
PR TIMES / 2024年11月19日 17時15分
-
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年11月18日 12時0分
-
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
ASCII.jp / 2024年10月28日 13時0分
ランキング
-
1AppleのSafariに関し、英CMAが「ブラウザ市場に悪影響」と調査勧告
ITmedia NEWS / 2024年11月25日 7時25分
-
2「上手いwww」 小学5年生、社会のテストで漢字をド忘れ→ひねり出した“天才的な回答”が240万表示「この子出世する」
ねとらぼ / 2024年11月25日 8時10分
-
3新機能がいっぱい!iPadOS 18で進化した「メモ」アプリを使いこなそう - iPadパソコン化講座
マイナビニュース / 2024年11月25日 11時34分
-
4Minisforumが「ブラックフライデー」を開催! 新商品も最大41%お得に買える
ITmedia PC USER / 2024年11月24日 0時0分
-
5「なんでだよww」 “究極のブルベメイク”をしてみたら……? 衝撃の仕上がりが1600万再生 「腹筋持ってかれた」「面白すぎるw」
ねとらぼ / 2024年11月24日 8時10分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





