

1万5000以上のチップレットを数分で構築する新技法SLTは従来比で100倍以上早い! IEDM 2024レポート
ASCII.jp / 2025年1月6日 12時0分
昨年12月7日~11日にかけ、サンフランシスコでIEDM(International Electron Device Meeting) 2024が開催された。前回と前々回に続いてこの内容について取り上げたい。
第3弾の今回は、Selective Layer Transfer。正式な名称は31-5の"Selective Layer Transfer: Industry First Heterogeneous Integration Technology Enabling Ultra-Fast Assembly & Sub-1um Chiplet Thickness for Next Generation AI & Compute Applications"という長いものである。
2枚のウェハーを重ねて接着して 1万5000以上のチップレットを数分で構築
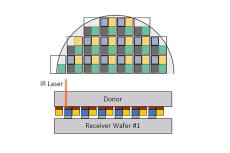
インテルのプレビューでのスライドが下の画像だが、そもそもこれはなに? というものだった。

この発表は、非常に小さなチップレット(それこそ上の画像にあるような1mm角のもの)を、きわめて高速にWafer on Waferの技法で、構築するのに赤外線レーザーを利用する、という内容である。
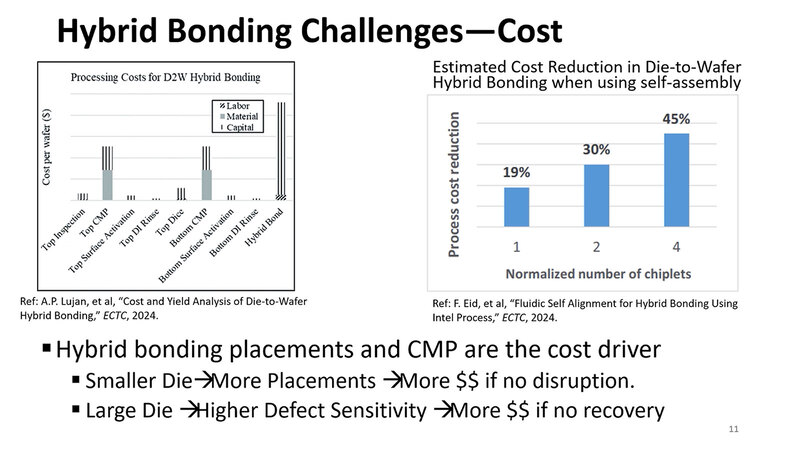
前回も触れたが、Hybrid Bondingは極めて有望なチップレットのための接続技術である。その一方で、「2つのダイの接続面が正しい位置関係にないと、うまく信号が伝わらないことになる。このための位置合わせの精度は1μm未満でないといけないわけで、これに猛烈な手間(とコスト)が掛かる」という問題が付きまとう。
特に難しいのは、チップレットのためのダイを一旦ウェハーから切り出し、改めて接続面をキレイにしたり、正確にインターポーザーなり別のダイなりとの位置を合わせて積層する作業である。
そもそも1mm角のチップレットの正確な位置合わせや、1mm角のチップのクリーニング、表面研磨という作業がとても難易度が高い。研磨にせよ位置合わせにせよ、1mm角という小さなダイに対して行なうことそのものが難易度を無駄に引き上げている。
加えるなら、300mmウェハーで1mm角のダイを取った場合、4万9000個弱(切り代0.2mmの場合)ものダイが取れる。ということはこの面倒な作業をウェハー1枚あたり4万9000回も繰り返すことになる。「数時間から数日」という上の画像の表現は大げさなものとは言いにくい。
こうした工程を効率化するために、WoW(Wafer on Wafer)の技法が提案されているわけだ。クリーニングなどはウェハー単位となるため、ダイ1個のクリーニングよりは時間がかかるにしても、4万9000回繰り返すよりは圧倒的に短時間で済む。位置合わせも、ウェハー単位で1回やればいいので、こちらも圧倒的に短時間である。
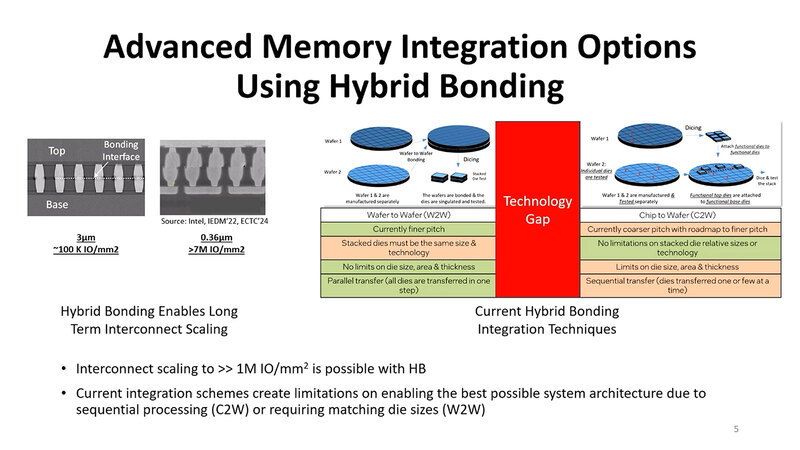
ただ従来のWoWの問題は、「同じサイズのダイでないと積層できない」ことだった。要するに2枚のウェハーを重ねて接着後に、まとめてダイシング(切り出し)をするから異なるサイズのものは載せられない。これはチップレットには少し使いにくい制約であった。今回の論文はこれに対する解決法を提案するものである。
サイズの異なるチップレットを積層する新手法 Selective Layer Transfer
基礎となるのは、すでに利用されている技法である。2つのダイを接着するにあたり、あらかじめILRF(IR Laser Release Film)と呼ばれている非常に薄い(1μm未満)フィルムをウェハー製造時に挟み込んでおき、最後にドナーウェハーを分離したい際に赤外線を当てることで簡単に分離できる仕組みだ。
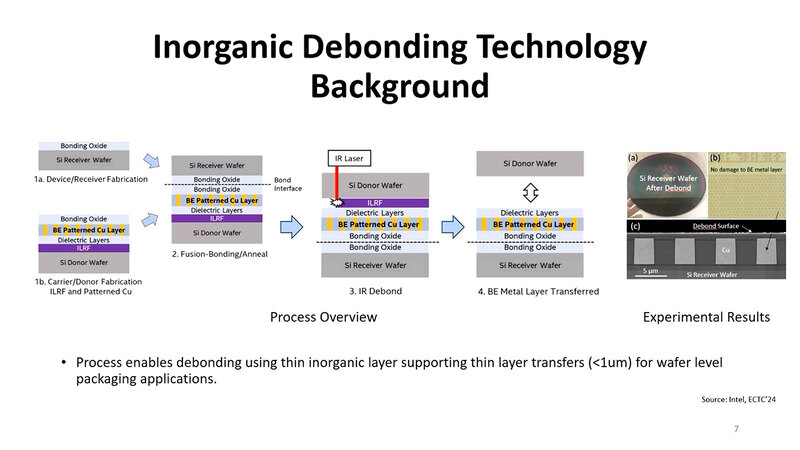
オーストリアのEVG(EV Group)はこれを利用したIR LayerRelease Technologyと呼ばれる解決策を提供しているし、このフィルムについてもさまざまなものがすでに提供されている。これを利用して、サイズの異なるチップレットを積層しよう、というのが今回の内容だ。
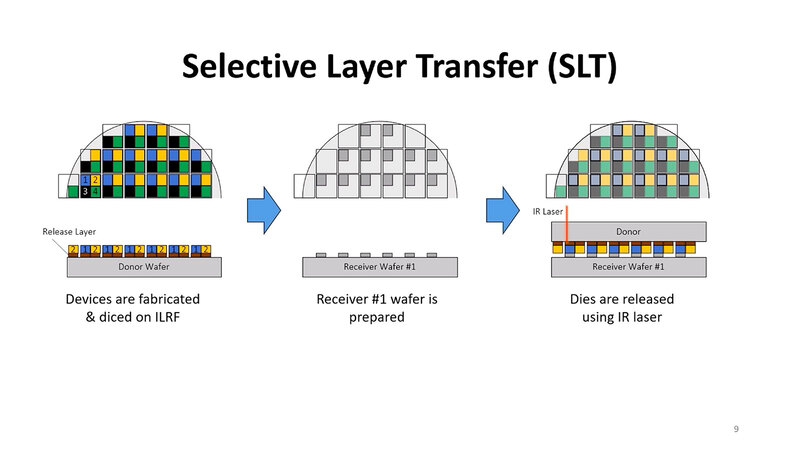
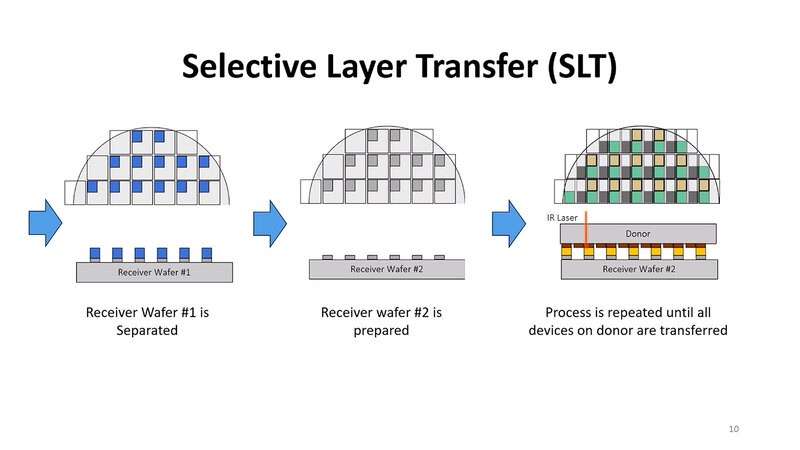
まず一番左がチップレットを構築したウェハーであり、#1~#4の4種類のダイがある。真ん中がそのチップレットを載せるレシーバーウェハーで、ここでは#1のチップレットを載せる用意がなされている。
右が実際に載せる際の手順で、ドナーウェハーをひっくり返してレシーバーウェハーの上に被せる。この状態で、ドナーウェハーの上からダイ #1の底の部分にだけ赤外線レーザーを当てると、そこだけフィルムがなくなり、ダイ #1がレシーバーウェハーに残る。
あとはレシーバーウェハー #1を取り外し、同じように今度はダイ #2を別のウェハーに載せるという形で、チップレットを全部転送できることになる。
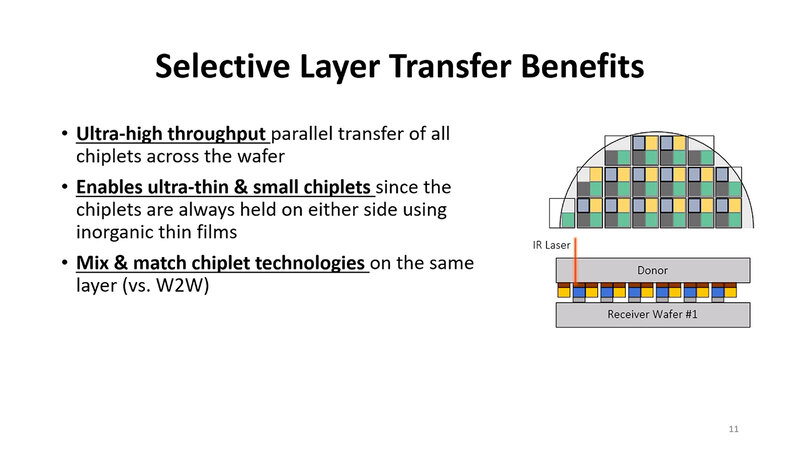
この方式のメリットはいくつかあり、当然スループットが早い(位置合わせの手間がチップレットの種類の数だけで済む)し、小さなチップレットであっても問題なく積層できる。
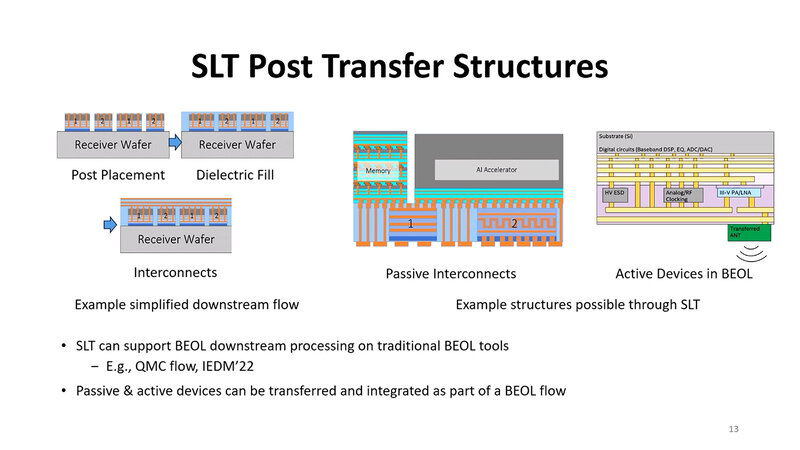
この後は、普通に誘電体を充填し、その上層にインターコネクトを積層することで完成である。これをもう少し応用すると、右側のように大規模なAIアクセラレーターを組み合わせたチップにしたり、あるいはIoT向けのチップをチップレットで作ったりすることも可能になる。
そもそも現在チップレットではあまり小さなサイズのダイを組み合わせることがない。これはダイサイズがある程度小さくなると、モノリシックで製造する方がトータルコストが安くなることに起因する。
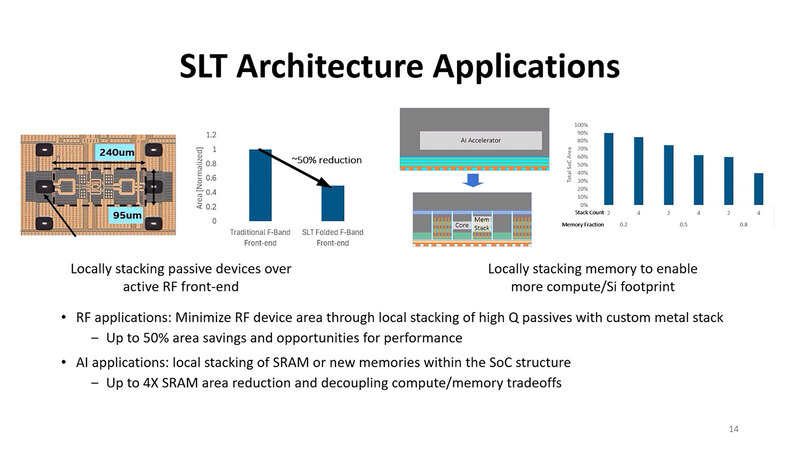
ダイサイズを小型化することによる歩留まり向上や、最適なプロセスを使うことによるダイサイズの最小化に起因するコスト削減より、チップレットを構築、検査するための追加コストの方が大きくなるからである。
検査はともかくとして、製造に関しては今回の手法を使うと大幅に下げられる可能性が出てくる。実際、簡単な試算ではあるが、例えばIoTなどに向けたRFフロントエンドでは50%以上の面積削減が可能だし、AI向けアプリケーションプロセッサーでもSRAMをどんどん積層することで大幅に面積削減ができる。
前回も触れた検査コストをどうするのか? という問題は残る(この論文はそこには踏み込まず、あくまで製造工程にフォーカスしている)ものの、大幅にチップレット構築のコストを下げられる可能性があるというのは、よりチップレットの普及を促進する要因になるだろう。
難点はウェハーの歪みだが ダイサイズが小さくなれば無視できる
まだSelective Layer Transferの技術にはいくつか難点がある。その最大のものが、ウェハーの歪みである。

上の画像の一番左がなにもしない場合のウェハーの歪みで、当然端に行くほど歪みが大きくなる傾向にある。これは当然今回も発生するわけだが、インテルによればチップレットの寸法が小さくなればなるほど、WoWの場合と同じ状況になる、としている。
歪みそのものは今さらどうしようもない(これの改善は今回のテーマではない)が、その影響はダイサイズが小さくなれば、その問題は無視できるという話であった。WoWと同じ傾向になるので、WoWと同じ方法で対処すればいいわけだ。
さまざまなパターンでの実装を試してみたが、概してうまくドナーウェハー上のダイがレシーバーウェハー側に転送できた、としている。

ちなみにスライドでは省かれたが、論文の方には、ダイ同士の間隔が大きい場合に上手くいかなかった例が示されているが、これは設計の最適化で対処できるとしている。

また他にも今回の技法の問題としてVoid(無効領域)の発生や、ダイの角の欠けなどが生じたケースもあるとする。ただきちんとパラメーターを合わせると、うまくダイを転送できることが実証されており、あとはプロセスの最適化を進めることで、これまでCoWでは発生しなかったこうした新しい問題の回避ができる、とまとめている。

で、記事冒頭の画像に出てきたものが下の画像だ。今回の技法の実証用に作られたドナー(チップレット)とレシーバー(ベース側)のウェハーを組み合わせた結果が右側である。レシーバー側のベースダイの大きさは4×4mm~8×8mmまで複数のサイズの組み合わせとなっており、この上に1mm角のチップレットダイを転送するというものだ。最終的には1万5000個以上のチップレットを転送できたとしている。

論文によれば、転送速度はおおむね毎時20万チップレットとしているので、今回の1万5000個のチップレットの転送にかかった時間は4.5分という計算になる。これは従来比で100倍以上の高速化になる、というのが今回の発表の肝である。
およそ200mm2以上のSoCなら 製造原価を大幅に下げられる
あくまでも今回は研究レベルの話なので、今すぐインテルの工場でこれを利用したサービスが可能というわけではない。ただこの方式が実用化されれば、チップレットの敷居がだいぶ下がることになる。実のところ、現時点でチップレットがメリットとして出てくるのは、モノリシックで200mm2前後以上のSoCに限られる。
例えばZen 4 RyzenではCCDが72mm2、IoDが122mm2なので、足すと194mm2になる。ギリギリ基準を下回るが、CCDが2個のRyzen 9では合計266mm2。
モノリシックでこれを作るとIoDの機能もTSMC N5での製造になるが、そもそもPHY(PCI ExpressやMemory I/Fなど)が含まれるからプロセス微細化の恩恵は受けにくい。強いて言えば内蔵するGPUが小型化されるのと、CCD/IoD間のインフィニティ・ファブリックのI/Fを省ける程度だが、それでも合計で200mm2を切るのは難しいだろう。
仮にモノリシックで200mm2(10×20mm)と仮定すると、1枚のウェハーから取れるのは最大300個、D0=0.1で有効ダイは240個となる(歩留まり80%)。ウェハーコストが1万7000ドルとして製造原価は70.8ドルほどになる。
一方チップレット方式では、CCDは876個中773個が有効となり歩留まりは93.1%、製造原価は22ドル。IoDは500個中429個が有効で、歩留まりは88.6%。製造原価は(TSMC N6の価格がTSMC N7と同程度だとすると)ウェハーコストは1万ドル程度なので、製造原価は23.3ドルほど。
これでRyzen 3/5/7のダイの製造原価は45.3ドル、Ryzen 9が67.3ドルということになり、Ryzen 9に関してはモノシリックとおおむね同等だが、Ryzen 3/5/7ではけっこうメリットになることがわかる。このあたりが現在チップレットを利用する場合の境であり、これより小さいものに関してはむしろ製造コストが上がることになる。
ただ今回の方式が広まれば、このしきい値(合計200mm2)をグンと下げられることにつながる。例えばSRAMの積層などを2層や4層にする場合でも、実装コストがそれほど増えないわけだ。
AMDの3D V-Cacheが32MB SRAMダイを2枚積層するのではなく、あらかじめ2枚のSRAMダイを焼き固めて1つの64MB SRAMダイにして積層する理由の1つは、この実装コストを最小に抑えるためだろうと考えられる。そう考えると、なかなか夢のある話であると言えるだろう。

この記事に関連するニュース
-
PCテクノロジートレンド 2025 - CPU編「Intel」と「AMD」
マイナビニュース / 2025年1月3日 10時0分
-
PCテクノロジートレンド 2025 - プロセス編「Samsung」と「Intel」
マイナビニュース / 2025年1月2日 10時0分
-
PCテクノロジートレンド 2025 - プロセス編「TSMC」
マイナビニュース / 2025年1月1日 10時0分
-
AI向けシステムの課題は電力とメモリーの膨大な消費量 IEDM 2024レポート
ASCII.jp / 2024年12月30日 12時0分
-
実は採用モデルが多いって知ってた? 「Ryzen AI 300」搭載PCから「FUJITSU-MONAKA」のモックアップまで見られるAMDのイベント「Advancing Al & HPC 2024 Japan」に行ってきた
ITmedia PC USER / 2024年12月13日 17時5分
ランキング
-
1GeForce RTX 50シリーズ正式発表!前世代から全モデル2倍の性能向上ってマジか
ASCII.jp / 2025年1月7日 15時0分
-
2知って納得、ケータイ業界の"なぜ" 第185回 値引き規制で一層冷え込む2025年のスマホ市場、大きく動くローエンドとハイエンド
マイナビニュース / 2025年1月6日 16時10分
-
3モバイルに「L3キャッシュ爆盛り」とApple/Intel対抗の「GPU強化モデル」登場――AMDが新型「Ryzen」を一挙発表
ITmedia PC USER / 2025年1月7日 6時0分
-
4パナソニックから光学30倍ズームのコンパクトデジタルカメラ ライカレンズと2030万画素のCMOSセンサー搭載
OVO [オーヴォ] / 2025年1月6日 7時41分
-
5HPが「OMEN MAX 16」など「CoreUltra 200HX」に「RTX 50」搭載の新ゲーミングPCを4機種発表
ASCII.jp / 2025年1月7日 13時0分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





