

「現在のLLMに真の推論は困難」──Appleの研究者らが論文発表
ITmedia NEWS / 2024年10月13日 8時5分

キウイの数の問題(Image Credits:Mirzadeh et al)
米AppleのAI研究者らは10月7日(現地時間)、「GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models」(LLMにおける数学的推論の限界を理解する)という論文を発表した。
この論文は、LLM(大規模言語モデル)が、本当に人間のように論理的に考えて問題を解けるのか、という疑問を検証している。結論としては、LLMは今のところ、表面的なパターンを真似て答えを出しているだけで、真の推論能力は持っていないと主張している。
研究者らは、これらの問題点を検証するために、「GSM-Symbolic」という新しいテスト方法を開発した。これは、LLMの数学的推論能力を評価するためのベンチマークデータセット「GSM8K」を改良し、問題の表現や数字を柔軟に変えられるようにしたもの。また、「GSM-NoOp」という、無関係な情報を含んだ問題集も作成し、LLMの推論能力を評価した。
実験の結果、OpenAIのGPT-4oやo1-previewなどのLLMは、他のLLMと比べて高い性能を示したが、それでもGSM-NoOpのような引っ掛け問題には弱く、真の推論能力を獲得するにはまだ課題があるとしている。
論文では、実験で明らかになった「弱点」を挙げている。
●数字や言い回しを変えると混乱する
例えば、ある問題をLLMが解けたとしても、その問題の数字を変えたり、少し言い回しを変えただけで、正解率が大きく下がった。
これは、LLMが問題の本質を理解して解いているのではなく、訓練データで見たパターンを単純に当てはめているだけである可能性を示唆している。
●問題が複雑になると混乱する
簡単な問題なら解けても、問題文が長くなって複雑になると、LLMの正解率は下がり、さらに答えのばらつきも大きくなる。
例として、公衆電話からの通話料金に関する問題をベースに、問題の難易度を4段階に調整した結果の正解率を、米GoogleのGemma 2や米OpenAIのGPT-o1 mini、米MicrosoftのPhi-3.5で調べたところ、いずれのLLMも難易度が上がると正解率が下がった。
4レベルの問題の内容は、以下の通り。一番上が最も簡単なものだ。
・電話ボックスから電話をかけるには、1分あたり0.6ドル掛かります。60分の通話料金はいくらですか?
-
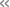
-
- 1
- 2
-

この記事に関連するニュース
-
Appier (エイピア)、人工知能に関する研究論文3本が、世界最高峰の学会「NeurIPS (人工知能、機械学習)」と「EMNLP (自然言語処理)」で採択
PR TIMES / 2024年10月17日 15時10分
-
【教員採用試験】「大阪エリア 数的処理 集中ゼミ」開講!
PR TIMES / 2024年10月11日 17時15分
-
「生成型AIによる医療革命」患者診断から治療まで支援…韓国IT企業も参戦
KOREA WAVE / 2024年10月4日 9時0分
-
世界一の日本語性能を持つ企業向け大規模言語モデル「Takane」を提供開始
PR TIMES / 2024年9月30日 16時15分
-
「BizTAP AI」ChatGPT OpenAI o1シリーズおよびDeepL翻訳機能実装のお知らせ
PR TIMES / 2024年9月25日 18時40分
ランキング
-
1Xのブロック機能や規約の変更後、Blueskyに50万人の新規ユーザー
ITmedia NEWS / 2024年10月19日 10時31分
-
2めざましテレビが「まいたけダンス」紹介→元ネタのVTuberに触れずさまざまな意見 「何も紹介が無いのは違う」「フリー素材扱いしたかったのかな?」
ねとらぼ / 2024年10月16日 17時34分
-
3「タップで早送り」「簡単操作で2倍速」YouTubeアプリを使いこなす!知って得する5つの裏技
よろず~ニュース / 2024年10月19日 11時0分
-
4【無料ゲーム】アマゾン「Prime Gaming」2024年10月の特典はこれだ
ASCII.jp / 2024年10月15日 17時0分
-
5リアム・ペインの急死巡り、“生みの親”と恋人へ批判が集中 「あなたのせい」「真実を話せ」と炎上状態に
ねとらぼ / 2024年10月18日 14時35分
複数ページをまたぐ記事です
記事の最終ページでミッション達成してください





