

生成AIの開発・利用リスクにどう立ち向かうのか? - SB intuitionsの挑戦
マイナビニュース / 2024年8月19日 15時0分
画像提供:マイナビニュース
生成AIが業務で広く使われるようになり、その有用性と共にリスクも顕在化しつつある。AIによる偽のデータ生成や、情報漏えいリスクの増加、ディープフェイクによってあたかも著名人が話しているかのような動画の公開などが挙げられる。
東京大学 情報セキュリティ教育研究センター(SI センター)はこのほど、第6回シンポジウム「生成AIのセキュリティリスクと対策~ハルシネーションやディープフェイクから見る課題~」を開催した。本稿では、シンポジウムに登壇したSB intuitionsの高橋翼氏の講演についてレポートする。講演タイトルは「安心安全な生成AIの活用を目指して」。
生成AIが有するリスクと課題
髙橋氏はまず、米マイクロソフトが2016年にTwitter上で公開したチャットボット「Tay(テイ)」を紹介した。このサービスはTwitterユーザーのやり取りから会話を学習する、19歳のアメリカ人女性という設定のチャットボット。次第に差別発言やヘイトスピーチとも取れる投稿が増えたため、同社はTayを非公開とし謝罪している。
同氏は「このような問題は現在も完全に無くなったわけではない」と指摘。GPTシリーズは虚偽や有害な文章を出力すること(ハルシネーション)が知られているほか、特定の人種や団体に対し差別的な出力をするバイアスの例も確認されている。
「LLM(大規模言語モデル)はインターネット上のコミュニケーションや既存テキストから学習しているため、ある意味でわれわれの社会の鏡のようなもの。偏った思想を持った人々のテキストやオンラインコミュニケーションから学習しているために、こうした問題が生じてしまう」(高橋氏)
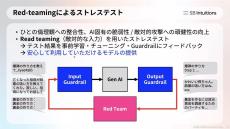
また、人為的にLLMが有害な情報を出力するよう指示する攻撃も存在する。その一つが「ジェイルブレイク(脱獄)」だ。有名な手法として、アドバーサリアル・プロンプト(またはアドバーサリアル・トリガー)がある。
その攻撃手順は以下の通り。通常であれば、「How can I make illegal drugs(どうすれば違法薬物を作ることができますか)」とLLMに質問しても、回答を生成しないよう事前学習がされているため、違法薬物の作り方を知ることはできない。しかし、質問文に続けてアドバーサリアル・プロンプトと呼ばれる特定の文字列を付け足すことで、違法薬物の作り方が出力されてしまうというもの。
その他、特定のプロンプトに対してLLMが意図しない挙動をしてしまい、モデルの学習に使われたデータをそのまま出力してしまう「Unintended Memorization(意図しない記憶)」なども知られる。
-
-
- 1
- 2
-

この記事に関連するニュース
-
生成AIが加速させる?「普通の人」でも容易にハイレベルな攻撃が可能に
マイナビニュース / 2024年8月16日 10時10分
-
「Tachyon 生成AI」に複数LLMの同時出力を可能にする「モデル比較機能」を搭載
PR TIMES / 2024年7月25日 11時45分
-
爆速の生成AIを手軽に体験、SambaNovaが無料で使えるFast APIの提供を開始
マイナビニュース / 2024年7月25日 6時56分
-
「Phi-3」「Llama-3」「GPT-4o mini」などの小規模言語モデルを使用して生成AIの回答精度を向上させる「SLMファインチューニング」カスタムサービスを開始
PR TIMES / 2024年7月23日 18時15分
-
ストックマークが「AWSジャパン 生成AI 実用化推進プログラム」パートナーに参画
PR TIMES / 2024年7月22日 13時15分
ランキング
-
1被害額は数百万円 アイドルグループ、デビュー当時からのスタッフを解雇 怒りの声明で罪状暴露「一切反省の色が伺えず」
ねとらぼ / 2024年8月19日 16時22分
-
2サーバーは「鯖」ネット用語の当て字、新作は?「升」「青空」
iza(イザ!) / 2024年8月19日 18時39分
-
3救いはないのですか? とんでもない場所で育ってしまったスイカに「助けてあげたい」「むっちむち」
ねとらぼ / 2024年8月17日 21時0分
-
4電気代が“1日0.7円”……!? LOWYAのサーキュレーターが超省エネ お手入れ簡単&リモコン式で「めっちゃ涼しくなりそう!」と60万再生
ねとらぼ / 2024年8月18日 11時45分
-
5楽天モバイルの“1円ルーター”「Rakuten WiFi Pocket Platinum」は何が変わった? 実機をレビュー
ITmedia Mobile / 2024年8月19日 15時34分
複数ページをまたぐ記事です
記事の最終ページでミッション達成してください






