

「ツイッターのおかげで共産党は躍進できた」そんなマスコミの選挙データ分析はなぜ失敗するのか
プレジデントオンライン / 2022年6月28日 10時15分

※写真はイメージです - 写真=iStock.com/gyro
■ツイート「拡散」が共産党躍進を生んだというデータ分析
次の図表1と新聞記事を読み、続く問いに答えてください。
毎日新聞と立命館大のネット選挙共同研究では、ツイッター利用者と各党候補者の投稿(ツイート)を収集・分析し、選挙への影響を検証してきた。これまでに共産党候補者のツイートがツイッター利用者による引用・転送(リツイート=RT)によって効果的に拡散し、民主党候補者のツイートはRTによる拡散力が弱い傾向が判明している。
共産党は12年ぶりに選挙区で議席を獲得。RT数が3万1000件に達した吉良佳子氏(東京)は70万票、2万5000件の辰巳孝太郎氏(大阪)も46万票を得た。落選者でもRT数1万件以上が4人おり、うち2人は得票数が25万票を上回った。比例当選者も2人がRT数1万件を超え、RTによる拡散力と得票数の相関が認められた。
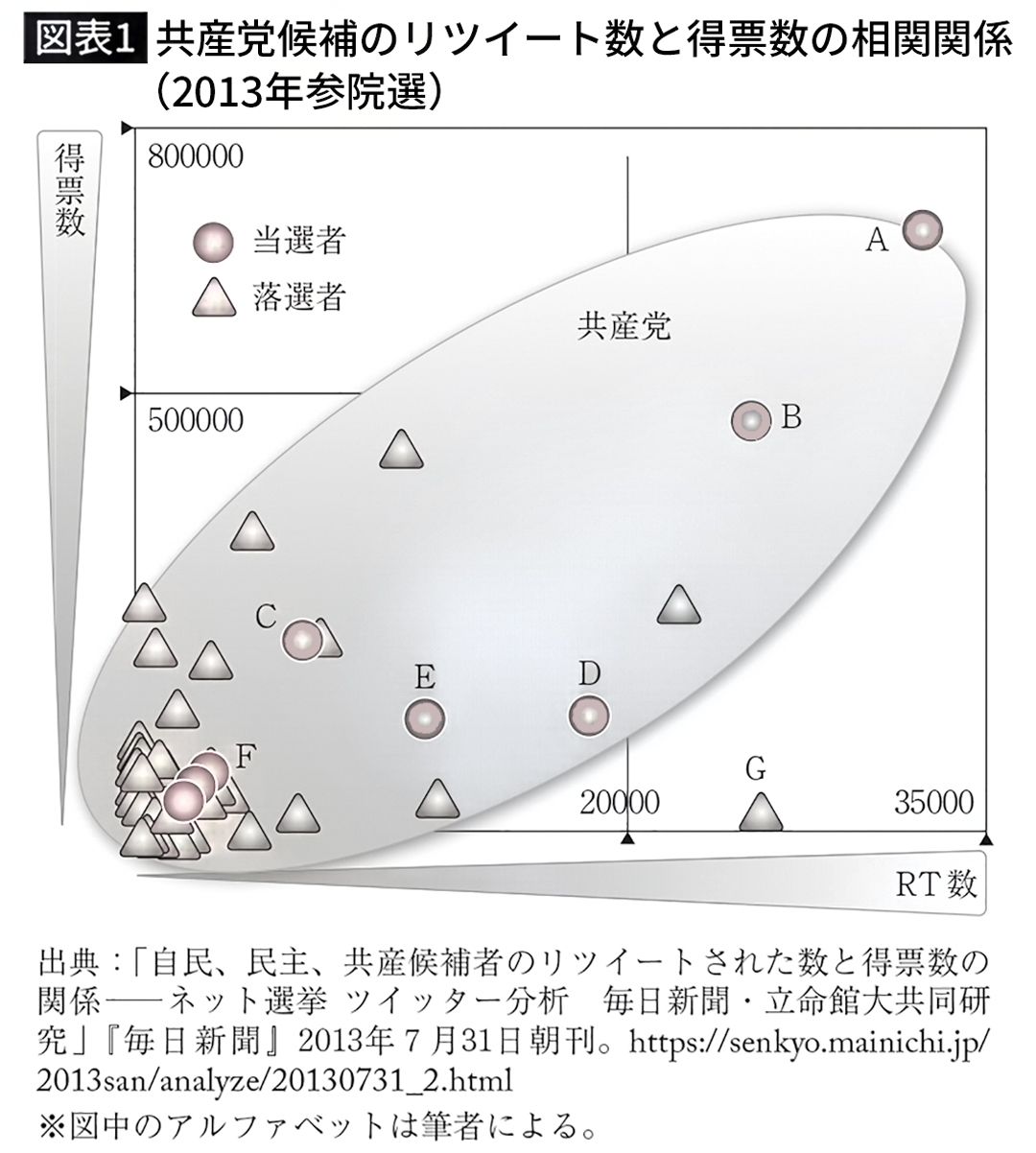
※引用元:「共産に『ネット効果』 本紙・立命館大分析」『毎日新聞』2013年7月31日朝刊(一部省略)
問 ネット選挙運動が当落に与えた影響を分析したとするこの記事は、共産党候補のツイッターへの投稿(ツイート、呟き)の拡散(リツイート、RT)が、共産党候補の当落や得票数に影響を与えたこと、さらには2013年参院選での共産党の躍進の要因であることを示唆しています。すなわち、共産党候補の当落や得票数を結果、呟きの拡散を要因とする因果関係の存在を主張したいようです。その根拠として提示されたのが、①RT数を横軸、②共産党候補の得票数を縦軸に配し、両者が相関しているように見える図表1の散布図です。
そこで、この①②共通の要因となる交絡因子を1つ提示することで、そのような因果関係は幻である可能性が高いと指摘してください。
注:交絡因子……2つの要素の間に相関関係を生み出す第3の要素
この先にはヒントとなる解説が書かれています。選挙権のない18歳未満の方、お急ぎの方、まだデータ分析に慣れてない方は、問題の内容を理解したらすぐに読み進めるとよいでしょう。
■ヒント① 参議院選挙の制度と結果
選挙について詳しくない方も多いと思いますので、簡単に参院選の制度と結果について述べておきます。これは、交絡因子探索のヒントでもあります。
参議院では全議員のうち半数ずつを、3年に1度の選挙で選んでいます。問題の記事が対象とした2013年参院選では、73人の議員を47都道府県別の選挙区で、48人の議員を全国一区の比例区で選んでいました。
都道府県別選挙区で選出される議員の数は、都道府県の人口に応じて選挙区ごとに異なります。最多の東京では5人(当時。2019年以降6人)の議員を選出した一方で、31の県では1人の議員しか選出していません。
比例区では、投票者は政党か政党が提出した名簿に記載された候補か、どちらかに投票します。政党が獲得した票は政党票、候補が獲得した票は個人票と便宜的に呼ばれています。この政党票と政党名簿登載候補全員の個人票を合算してその政党の得票とし、その数に応じて比例的に各党に獲得議席を配分します。2013年の選挙では、各党の中では個人票の多い候補から順に配分議席数まで当選する方式が採用されていました。
2013年参院選で共産党は、都道府県別選挙区では沖縄以外の46選挙区に各1名の候補を擁立し、東京(5人区)、京都(2人区)、大阪(4人区)の各選挙区で議席を獲得しました。17人の候補を名簿に登載した比例区では、約10%の得票率で5議席を獲得しました。
比例区の制度はやや複雑で共産党の候補者数も少ないので、都道府県別の選挙区に限定して考えるとわかりやすいでしょう。

■ヒント② フォロワー数が多ければリツイートも多くなる
ツイッターでは、ユーザーは他のユーザーを「フォロー」します。そうすると、フォローしたそのユーザーの投稿が自分自身の「タイムライン」に自動的に配信されてきます。読んだ投稿を「リツイート」すれば、自分をフォローしている人=「フォロワー」にその投稿を再配信することもできます。
興味を引く、自分が賛同する、あるいは酷い内容のツイートを、各ユーザーはリツイートします。強い反応を呼び起こすような投稿は、連鎖的にリツイートされていきます。これを記事のように「拡散」と呼んだりします。
なお、あるユーザーをフォローしていなくても、多くの場合はそのユーザーの呟きを読むことができます。ただし、リツイートで再配信されてこない投稿は、わざわざそのユーザーのページに読みに行かなければなりません。逆側から見れば、自身の投稿がリツイートされるか、そしてどれだけ拡散されるかは、まず自分のフォロワーがどれだけいるかにかかってきます。フォロワー数の多い人気ユーザーであれば、それだけリツイートも広がりやすいのです。
したがって、リツイートの数は基本的にその人のフォロワーの数によって決まると言えます。つまり、フォロワー数が少ない人よりも多い人のほうがリツイート数は多くなるのです。
■データ分析の解釈を狂わせる「交絡因子」の見抜き方
問題では図表1の横軸(RT数)と縦軸(共産党候補の得票数)に共通する交絡因子を求めています。交絡因子とは、「結果と要因の間に割って入ってきて三角関係を作る別の要因」です。交絡因子という特殊な名前がついていますが、因果構造の一角を占める要素のひとつに過ぎません。
因果構造を考える際に大切なのは対象に関する知識です。したがって、交絡因子を探す際にまず必要なのも対象に関する知識です。今回は必要な知識を提供するために、ヒントを先に示しておきました。これらの知識も踏まえつつ、この問題を解いていきましょう。
交絡因子を考える際、最初から2つの要素に共通する要因は何か? と考えてもうまくいかないことがあります。このような場合には、一方の要素の因果構造を考え、その中で他方の要因となりそうなものはないか考えるのがよいです。
ここでは、焦点となっている2つの要素のうち、知識があり想像が容易い側の要素について先に背景の因果構造を考えていき、その中でもう一方の要素と繋がるところはないか確認していく思考戦略を採用します。
今回は、先に「候補の得票数」に連なる因果関係を考えてみます。まず直接的な要因を考え、次にその奥の間接的な要因を考えてみるという因果構造の探り方を適用してみましょう。候補の得票数が多くなるのはその候補の支持者数が多いからだといったような、言い換えに近い因果関係を思い浮かべるわけです。
ただし共産党は、候補者個人を支持して投票したという人より、共産党の候補であれば誰でも投票するというような人が多いでしょう。ちなみに政治学では、このような投票行動を「箱推し」と呼びます(嘘です)。
■得票数を大きく左右するのは都道府県の人口
ともかく、その選挙区における共産党や候補独自の支持者の数が多ければ、共産党候補の得票数も多くなると考えることができます。もっとも、支持者がたくさんいるので得票も多いという因果関係は直接的で当たり前すぎますから、さらに支持者の数の背後の要因を考えることになります。真面目に考えれば、農村部では共産党の支持者は少ない、貧困層が多い地域では共産党の支持者が多い等々と思いついていくことになるでしょうか。
しかし、もっと強力な要因があります。それは都道府県の有権者数(≒人口)です。
参議院の選挙区は都道府県ごとに分かれていますが、その都道府県の人口は最少と最多で20倍以上の開きがあります。仮に人口最少の鳥取県で共産党支持率が40%だったとしても、その支持者の数は人口最多の東京都での支持率わずか2%の場合と同程度ということになります。人口格差はこのように強い影響を及ぼします。したがって、鳥取県で出馬した候補がいかに頑張って得票“率”を上げても、東京都で出馬した候補が獲得するのと同程度の票“数”を獲得するのはなかなか難しいのです。
前提知識がないと、都道府県の人口が支持者の数や候補者の票数に影響することには気が付きにくいかもしれません。おそらく最も簡単に気が付ける方法は、実際の選挙結果を眺めてみることでしょう。共産党候補の得票数が、東京や大阪で多く鳥取や島根で少ないと知れば、都道府県の人口が候補者の得票数の根本的な要因ではと思い当たるでしょう。
そのほかの要因も考えてみましょう。候補の得票数は、党の支持者数や候補個人の支持者数から影響を受けるだけでなく、他の候補の得票状況からも影響を受けます。以下、少し議論を省略しますが、他の条件が同じなら、他党の有力候補者数が増えるほど共産党候補の得票数は減ることになります。
共産党以外から有力候補がどれだけ出馬するかは、選挙区の選出議員数に左右されます。参院選挙区では選挙区によってその選出議員数が異なり、選出議員数が多いほど他の有力政党から出馬する候補の数が多くなります。そして、参院選挙区の選出議員数は、選挙区(都道府県)の人口の多少で決まっています。
■支持者の多い候補はフォロワー数、リツイート数も多くなる
「候補の得票数」の因果構造がだいたい見えてきたら、次に「リツイート数」の因果構造も考えてみます。ここでは「候補の得票数」の因果構造を先に考えているので、その中の各要因を交絡因子の候補と捉え、これらが「リツイート数」にどう絡むのか同時に考えると効率的です。
たとえば、リツイート数の要因として、各候補のフォロワー数やツイート数という要素を思いついたとしましょう。ここでさらに、各候補のフォロワー数の多少を決める要因として、先に考えた因果構造の中から党支持者数や候補独自の支持者数を繋げることができれば、これらが交絡因子の候補になります。
あるいは、「逆方向の因果関係で捉えてみる」という方法を用いてもよいでしょう。つまり、「候補の得票数」が「リツイート数」の要因となっているのではないかと一度考えてみるのです。得票数が多い候補にはそれだけ支持者の数が多いのだから、ツイッターのフォロワー数も多くリツイート数も多くなるのではと、この2つの要素を因果関係で結ぶように考えていきます。すると、「リツイート数」、「候補の得票数」それぞれが第3の要素「候補の支持者数」を起点とした矢印で繋がりますから、これを交絡因子の候補とすることができるでしょう。
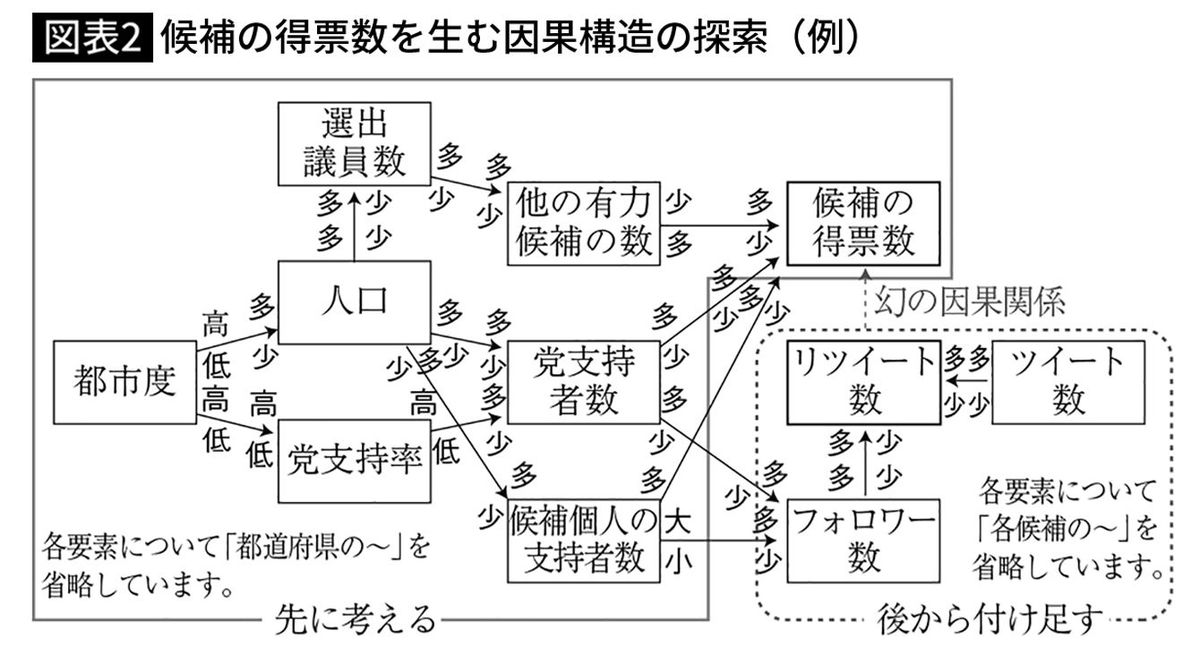
図表2は、以上のような思索を経て作成した因果構造の図です。あくまで一例ですが、ここで焦点となっていた「候補の得票数」と「リツイート数」とを、「党支持者数」や「候補個人の支持者数」から伸びた矢印で繋げることができました。議論としては、図表1はリツイート数が得票数を伸ばすような因果関係を示すものではなく、党支持者数などを交絡因子とした偽の相関関係を示したものだ、と指摘することになります。
ここで一度、解答例を示しておきたいと思います。
この記事では、共産党候補の呟きの拡散が共産党候補の得票や当落に影響を与えたという因果関係を主張している。しかし、その根拠となる散布図は共産党候補の呟きの①リツイート数と②得票数の相関関係を示すに過ぎない。
たとえば東京都のような人口の多い選挙区では、鳥取県のような人口の少ない選挙区に比べて共産党支持者の数はかなり多く、同党候補の得票数も遥かに多くなる。同様に、東京都のような人口の多い選挙区では、鳥取県のような人口の少ない選挙区に比べて各党候補をフォローする支持者の数がかなり多くなり、必然的にリツイート数も多くなる。党の政策の宣伝のようなほぼ同じツイートでも、大都市圏の候補と小県の候補とでは、そのリツイート数は大きく異なることになる。
このように、選挙区間で大きく異なる党支持者数を共通の要因としているため、①リツイート数と②得票数が相関するのは当然である。すなわち、①②間の相関関係は党支持者数を交絡因子とする偽の相関関係と考えられ、①から②への因果関係を主張するのは誤りと考えられる。
■誤ったデータ分析が新聞に掲載されてしまう理由
ところで、なぜこのような誤ったデータ分析が新聞に掲載されてしまったのでしょうか? ここには、怪しい分析が世に流通してしまう背景が垣間見えます。
まず直接的には、記者らにデータ分析に関する素養や対象に関する知識(この場合は選挙制度や政治に関する知識)が乏しかったことが要因と考えられます。交絡因子なるものが偽の相関関係を生み出すことを知らなければ、単純な散布図から容易に幻の因果関係を掴んでしまうのです。
マス・メディアに限らず、これらはデータ分析を失敗に導くよくある要因です。新聞社の場合はそもそも文系学部出身者が多いこと、そして入社後は取材と執筆の積み重ねの一方でデータ分析に関するトレーニングの機会や動機がおそらくほとんどないことも背景として想像できます。
さらに、新聞特有の事情もあります。それは、単純な分析結果しか示すことができないという媒体の縛りです。
新聞記者は、「一般の読者がわかる記事を書かなければならない」と自分自身を戒めているところがあります。これはデータ分析に限りません。筆者個人の印象ですが、取材や原稿のやり取りのときに、自分がわからないものは読者もわからないはずという謎の驕りを新聞記者から感じることがあります。
ただその結果、難しいことをわかりやすく伝えるのではなく、最初からわかりやすいことばかり並べたり、だいぶ単純化して物事を伝えているのではないかと疑問に思うこともあります。近年は大学の授業も同様の風潮があるように思いますが。

■「わかりやすさ」の呪縛がデータ分析を狂わせる
そうした「わかりやすさ」の呪縛がデータ分析に向かうと、散布図を代表とする2つの要素間の関係のみを示す単純なグラフばかりが新聞に載ることになります。一応述べておけば、散布図は単純で便利で有意義なツールで、使っていけないことはありません。丁寧に因果関係を読み解くなら、分析と議論の良いお供にすることができるでしょう。
しかし、鍛錬していない人が散布図を用いると、グラフ上に表現された2つの要素のみに焦点を当て、単純で誤った議論を展開してしまいがちになります。
一方、社会に存する現象は本来複雑な背景を持つものです。2つの要素の関係を見るだけで因果関係を主張できるほど都合よく社会はできていません。だからこそ因果の構造を熟考することが重要なのです。
ともかく、散布図を根拠としてそこに登場する2つの要素間の因果関係を主張するような「分析」を見たら、何かあるはずだと交絡因子を疑って読むことを心掛けるとよいでしょう。
■多くのメディアがツイッター分析に飛びついた理由
出題の記事が生まれた過程にも注目してみましょう。データの出所に分析結果を読み解くヒントがあることはよくあります。
見出しに「共同研究」とあることからわかったかもしれませんが、出題した記事は社外との共同プロジェクトの成果のひとつとして書かれたものです。
記事が対象とした2013年参院選でマス・メディアは、この選挙から解禁された「ネット選挙」を話題にしました。それまでネットを用いた選挙運動には強い規制があり、たとえば候補者は自身への投票の呼びかけすらネットではできませんでした。この規制が緩和され、候補者や支持者がネットを用いて選挙運動を行うことがある程度できるようになったとき、ネット上でどのような運動が展開されるのかということに、新聞各紙は注目していました。
このことを示すのが、新聞各紙と通信社の紙面やウェブで展開されたツイッター分析企画です。人々や政治家の呟きを分析してネット選挙運動の効果や実態を明らかにしようと、各社ともいろいろ試みていました。
さて、ここで勘の働く方は「ネットは様々なのに、なぜ各社ともツイッターの分析をしたのだろうか?」と疑問に感じたと思います。根本的な理由としては、そのオープンな性質から、他のSNSに比較してツイッターの呟きはデータが入手しやすいことが挙げられます。データがなければ分析できないので、当時流行りの“ビッグデータ”が分析できたツイッターがマス・メディア各社に重宝されたわけです。
■ビッグデータを取り扱う企業の登場
それでは、この呟きのデータはどこから来たのでしょうか? もちろん、マス・メディア各社が独自に独力でデータを収集したわけではありません。“ビッグデータ”が流行語となった当時、ツイッターの呟きを収集、分析し、マーケティングなどに活用するビジネスを立ち上げた企業がいくつか出てきていました。そうした有名無名の企業がマス・メディア各社にデータを提供したのです。
当然、単にデータを販売して利益を得ることだけが各企業の目的ではないでしょう。各企業の思惑を勝手に想像すると、権威のあるマス・メディア各社にデータを使ってもらえれば、それを実績として誇示することができる点が大きかったはずです。また、提供元として記事等に自社やブランドの名前が出れば宣伝にもなります。もちろん、こうした思惑を企業が持つことは普通のことで、それが悪いということではありません。
■デジタル読者獲得施策として持て囃されたツイッター分析
一方、“紙離れ”に危機感を抱いていた新聞社、通信社は、デジタル版の読者獲得を狙い、ウェブ向けの企画に力を入れていました。ウェブで“映える”グラフを作りやすいツイッター分析は、まさにこの目的に適っていたと言えるでしょう。
マス・メディアによる日本の選挙に関する大規模なツイッター分析のおそらく最初の例は、朝日新聞が「ビリオメディア」(注1)と名付けた企画の中で、2012年衆院選を題材に行われたものです。ビリオメディアとは「10億(ビリオン)を超える人たちがソーシャルメディアで発信する世界」を示す同社による造語です。
注1:「朝日新聞デジタル」http://www.asahi.com/special/billiomedia/
当初は、記者がSNS(ツイッター)を利用することで取材過程をオープンにしながらSNSに関する記事を書くというのが企画の趣旨だったようです。そこに「ビッグデータ分析」という名前でツイッター分析が加わり、企画の二本柱となったようです(注2)。
注2:「ビリオメディアって何?/朝日新聞が何かやってます」togetter
おそらくこの企画を見て、他社もこぞって真似たのが2013年参院選のツイッター分析の流行の実際です。各社とも企業からデータの提供を受け、大学教員も使いながら、紙面とウェブで企画を展開していました。
ただ、それらの企画の中で提示された分析の水準は正直に言って酷いものでした。これについては筆者がかつてまとめて批判したことがありますので、興味ある方はそちら(注3)を参照してください。
※注3:菅原琢「『ネット選挙』から見る政治報道の課題と展望」『Journalism』2013年9号、88-97ページ
■マスコミは「効果あり」を大きく報じてしまいがち
しかし、メディアと企業、大学教員など多人数が関わった大きなプロジェクトであるのに怪しいデータ分析が生み出されたのはなぜでしょうか。おそらくそれは、それこそ「大きなプロジェクトだったから」ではないかと筆者は考えています。
研究者の間では、出版バイアスという言葉が知られています。簡単に言えば、否定的な分析結果よりも肯定的な分析結果のほうが公表されやすいことを指します。
たとえばある成分がある病気を治癒する効果があるとは言えない(以下、「効果なし」と短絡的に言い換えます)とする分析結果が出たとき、効果があってほしいと思っていた分析者はそれを論文にせず、「効果あり」とみなせる分析結果が出るまで実験するかもしれません。そういう人は、「効果あり」の分析結果が出たときに、別の交絡因子が作用している疑いがあってもそれを無視したりするかもしれません。ときにはデータを捏造(ねつぞう)してでも「効果あり」にする研究者さえいます。

これと同じようなことがマス・メディアでも起きていたと想像することができます。大きな予算を使って、プロジェクトを組んで、紙面とネットで大々的に企画を展開したら、どうしても「効果あり」を大きく報じてしまう傾向があるということです。これは世論調査の結果を公表する際にしばしばみられることで、大きな数字は見出しに載せて大きく報じ、小さな数字には触れないといったことが起こります(注4)。
※注4:菅原琢「世論調査政治と『橋下現象』――報道が見誤る維新の会と国政の距離」『Journalism』2012年7号、38-47ページ
仮に「効果なし」を示唆するグラフを見ても「ネット選挙は意味がありませんでした」と記事にすることは難しく、逆に「効果あり」と感じさせるグラフが見つかれば即採用となりやすかったのではないかと想像します。「効果あり」の記事を出せと強い圧力を受ける現場の記者は訓練された研究者とは異なり、容易く「効果あり」を拾ってしまうのでしょう。
以上の考察を踏まえると、世に流通するデータ分析の失敗に敏感になるためには、データ分析自体を批判的に見るのに加え、データの出所やその分析が生まれ出てきた背景に着目することが有効だと言えます。誰が何のためにデータを作成したのか、どういう目的で分析が行われたのか考えを巡らせれば、見えてこなかったものが見えてくることがあります。
----------
政治学者
東京大学法学部卒、同大学院法学政治学研究科修士課程、博士課程修了。博士(法学)。専門は政治過程論、日本政治。国会議員の国会での発言、活動などをまとめる国会議員白書を運営。著書に『世論の曲解』、共著に『平成史【完全版】』、『日本は「右傾化」したのか』などがある。
----------
(政治学者 菅原 琢)
外部リンク

この記事に関連するニュース
-
高市早苗氏に〝包囲網〟リーフレット送付問題、首相が選管に「追加対応」求める 自民総裁選での急伸に他陣営が焦り?
zakzak by夕刊フジ / 2024年9月19日 15時30分
-
予備選挙で各党の候補者決定、本選は538人の「選挙人」獲得を競う 米大統領選の仕組み
産経ニュース / 2024年9月11日 14時40分
-
<早くも“解散”予告>自民総裁選「進次郎でほぼ決まり」は本当か? 気になる自民党内での温度差…参院議員は「衆院はいい。我々は生き残れない可能性がある」
集英社オンライン / 2024年9月6日 16時0分
-
自民党総裁選 道内議員の動向は?野党は?そして注目の選挙区はどうなる
HTB北海道ニュース / 2024年9月4日 20時17分
-
ポスト岸田「1位石破茂、2位上川陽子、3位小泉進次郎」は大ウソ…自民党支持者だけに聞く「次の首相」ランキング【2024上半期BEST5】
プレジデントオンライン / 2024年9月3日 8時15分
ランキング
-
1遺体の頭を金属の棒で突き、頭蓋骨が崩れる…岐阜市斎苑「きれいに火葬するためだった」
読売新聞 / 2024年9月20日 12時33分
-
2歌舞伎町で若い男女2人死亡 ホテルの外階段から転落か
毎日新聞 / 2024年9月20日 11時17分
-
3一家3人殺害、孫を鑑定留置=来年1月まで―静岡地検支部
時事通信 / 2024年9月20日 15時6分
-
4「10・27衆院選」は小泉進次郎首相になっても困難か "本命"「11・10」だが、米大統領選後解散の可能性も
東洋経済オンライン / 2024年9月20日 9時30分
-
5官僚に聞いた「首相になってほしい人物/なってほしくない人物」。“高圧的”と噂のある候補は軒並み不人気
日刊SPA! / 2024年9月20日 8時54分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





