

「日本人の平均所得が552万円というのは高すぎる」そんな直感の正しさを裏付ける"平均のウソ"
プレジデントオンライン / 2022年7月7日 8時15分

※写真はイメージです - 写真=iStock.com/metamorworks
※本稿は、松本健太郎『データ分析力を育てる教室』(マイナビ出版)の一部を再編集したものです。
■「おかしな結論」は間違ったデータが原因の可能性大
数字を用いた論証をするなら、数字自体が正しいかチェックするべきです。
なぜなら、数字自体が間違っていたら誤った結論を導くからです。
数字自体は間違っていなくても、計測の過程で間違うことはよくあります。
わたしは以前、人間の表情から感情を推測する機械を活用したデータ分析に携わりました。1人の表情に対して喜び70%、悲しみ15%、怒り5%……など様々な感情が割合で表示されるのですが、数字をチェックしてみると、1人で1000%を超えるデータが混ざっていました。
これでは正確なデータ分析はできません。
こんな経験もありました。
自動で重さを測る機械を活用したデータ分析に携わった際、どうしても納得のできる結論を導けなくて、仮説が間違っているのではなく、数字が間違っているのではないかと考え直しました。
そこで数字の間違いを証明するために、わざわざその機械の計測現場に足を運んだのです。
すると、30秒に1回、その機械は誤作動を起こしてデタラメな数字を記録していたことがわかりました。
■データの「定義・意味」「傾向」をチェックする
わたしは長年の経験で「間違っていないデータはない」と考えています。
機械の不具合、人間の勘違い、入力ミス等で誤ったデータが紛れ込むこともあれば、「定義」「意味」が違ったせいで、誤った解釈でデータを捉えることもあります。
データが間違っていないか、チェックする際は、
②傾向の確認
をすると良いでしょう。
定義・意味の確認は意外と忘れがちなので、分析に取り掛かる前に必ず確認するくせを付けた方が良いでしょう。
例えば、スイーツカテゴリの売上が昨年比50%減だとわかったとします。
しかし、実はその原因は、主力商品の「フレンチトースト」が、今年からスイーツカテゴリではなく、ランチカテゴリで集計することになったからだった、みたいな話がよくあります。
定義・意味の確認をすることで、こうしたミスを防げるようになります。
傾向の確認をするには、手元にある数字の内訳を見ます。
例えば、あるスーパーの購買データを分析するにも、時間別の売上、売れ筋商品の傾向を知っておけば、購買データ1件1件を見ずとも「だいたい、こういう傾向にあるな」と判断が付きます。
■「データの偏り」があると「平均」がずれる
数字の傾向を知るための方法を「要約」と言います。
「要約」で知っておくべきは、「平均」、「中央値」、「標準偏差」の3種類で十分です。
「平均」とは数字の集まりの中間、真ん中の値という意味があります。
数学的には、集合の要素の総和を集合の要素数で割った値を意味します。
例えば体重が50kg、60kg、70kgの3人がいたとして、体重の「平均」は
となります。
「平均」を求めると「真ん中はだいたいこれぐらいなんだなぁ」とわかります。
ちなみに、「平均」には大きな欠陥があります。
それは数字の集まりに偏りがあると、真ん中を意味しなくなるのです。
例えば、厚生労働省が発表している国民生活基礎調査によると、2018年の全世帯を対象にした平均所得金額は552.3万円だとわかりました。
多くのサラリーマンが「みんな本当にそんなに稼いでいるの?」と声を荒げたのではないでしょうか(図表1)。
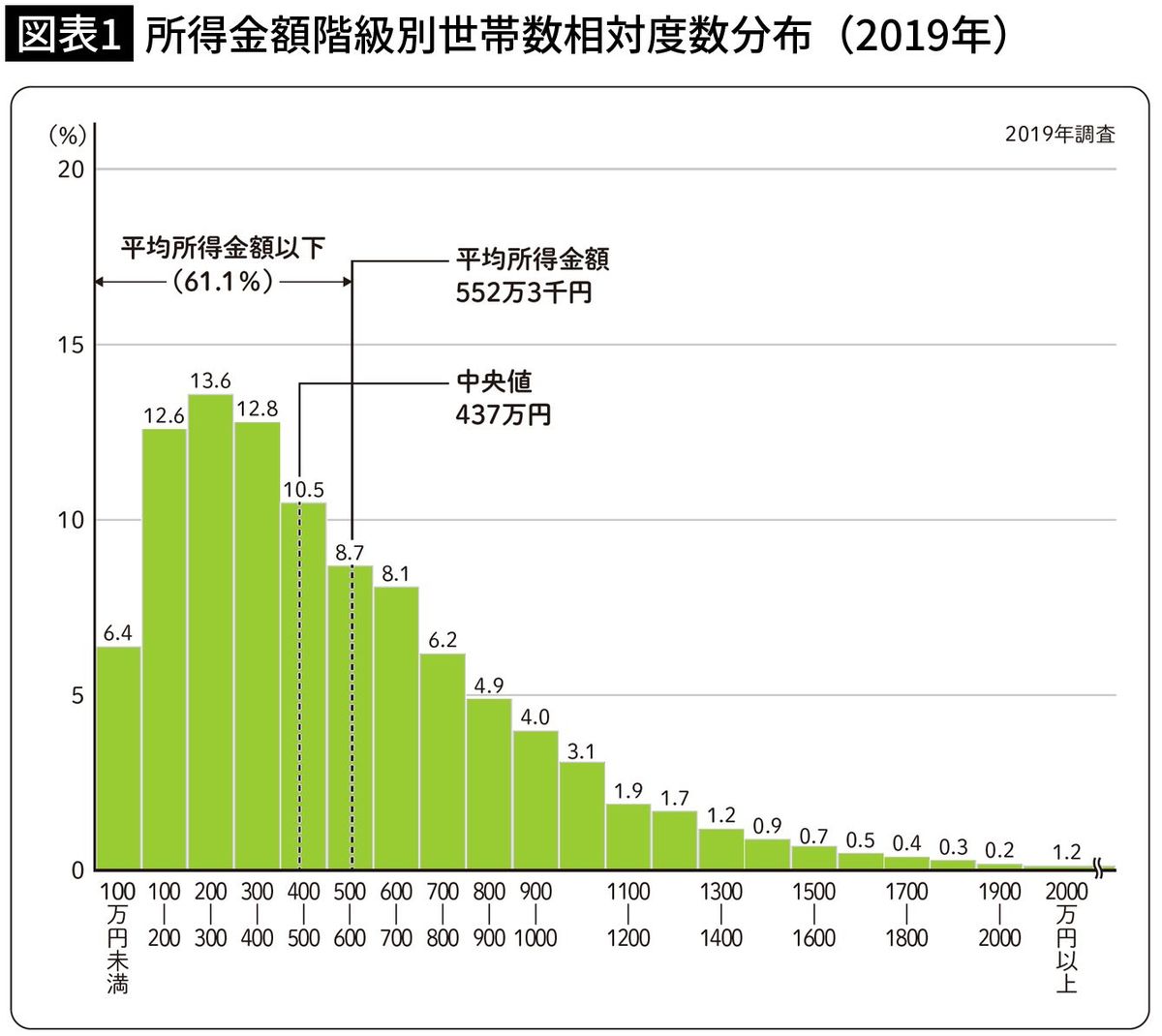
グラフを見ると、平均所得金額が「100万円未満」は6.4%、「100~200万円」は12.6%とわかります。
「1000~1100万円」は3.1%、「2000万円以上」は1.2%もいます。
「2000万円以上」の中には3000万円の人や、1億円の人もいるでしょう。
集合の中に、たった1つでも、頭抜けて高い値があると、それが平均を高く押し上げる要素になります。
現象を単純化します。
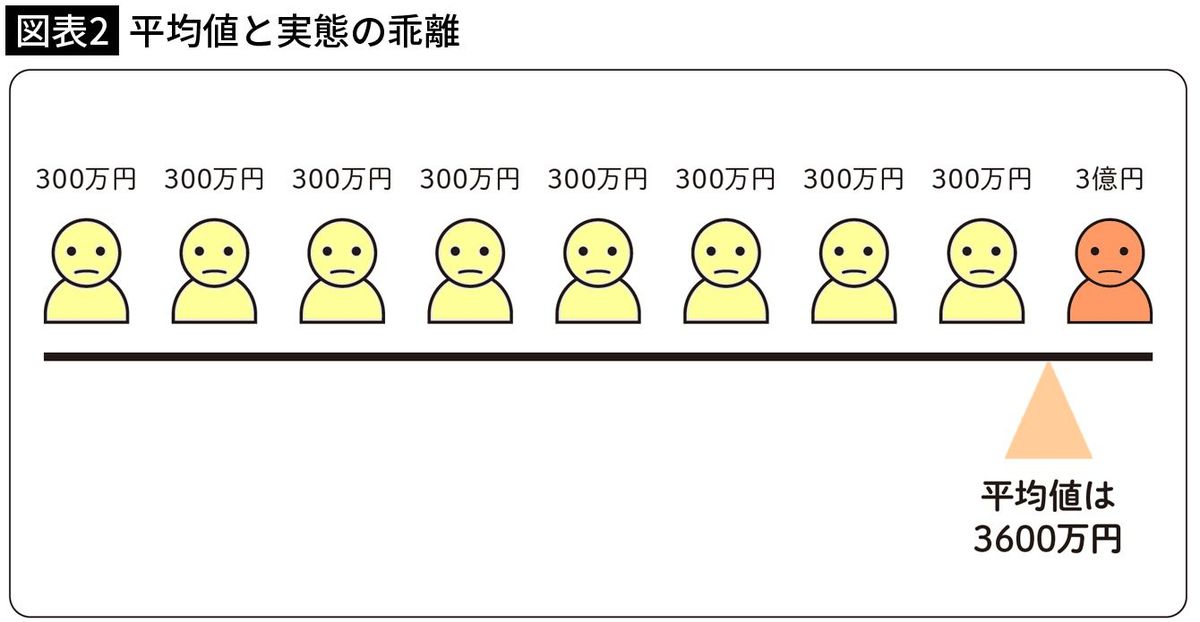
9人の所得金額のうち、8人が300万円でも、残り1人が3億円なら、平均所得金額は3600万円になります。
集合の要素の総和を集合の要素数で割った値という数学的な求め方として間違ってはいないのですが、3600万円が「真ん中」とは感じません(図表2)。
■「所得の真ん中」は「中央値」で見るべき
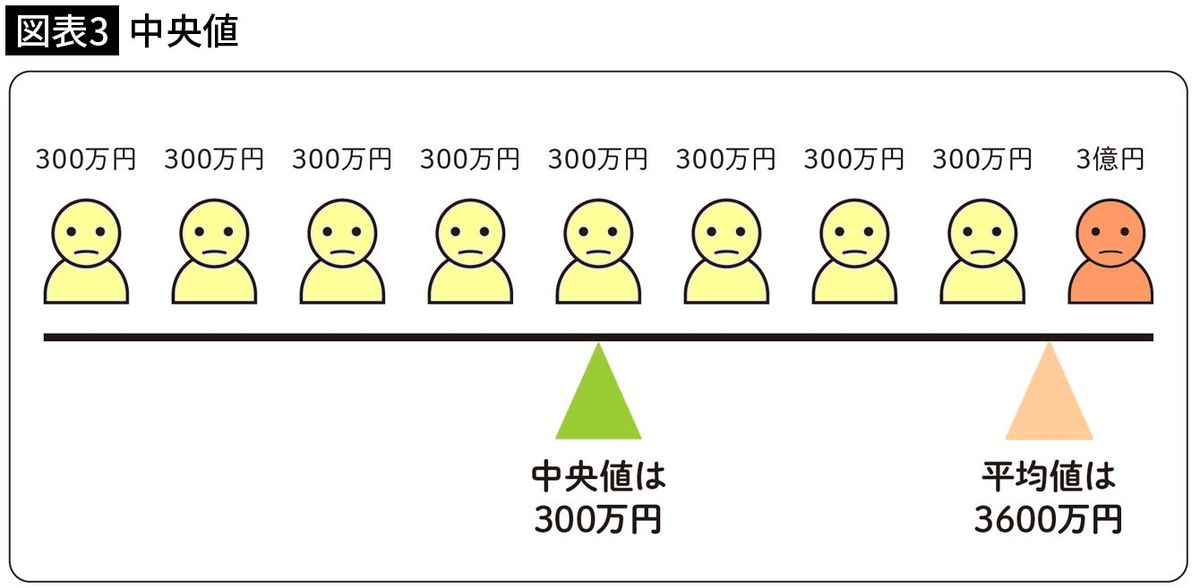
そこで、中央値を求めます。
中央値は平均と同じように、数の集合の中間、真ん中の値という意味があります。
ただし数学的には、データを大きい順に並べた時の中央の値を意味しています。
例えば、先ほどの9人の所得金額で言えば、5人目の金額が中央値を意味しています。
平均よりは実態に近いのではないでしょうか(図表3)。
国民生活基礎調査から引用したグラフでは、中央値は437万円と記載されています。
平均の差分は約115万円になります。
すなわち、9人の所得金額の例で見たように、べらぼうに高い所得の人間が混じっているということです。
ある特定の範囲内の数字の集まりの真ん中なら平均、そうでなければ中央値、と考えても良いかもしれません。
■意外と知らない「偏差値」の中身
最後に標準偏差です。
「標準偏差」には、平均値からの散らばり具合という意味があります。
数学的には、分散の非負平方根でも求まります。
急に難解になったので、具体的な例を紹介します。

全国統一模試における、わたしの得点が150点満点で70点だったとします。
ただし、平均点は80点でした。
「まぁ、惜しかったな」でしょうか、それとも「かなり点数は低い」でしょうか。
特に入試などの合否判定は、実際には得点では決まらず、上から数えて何人目の得点かで決まります。
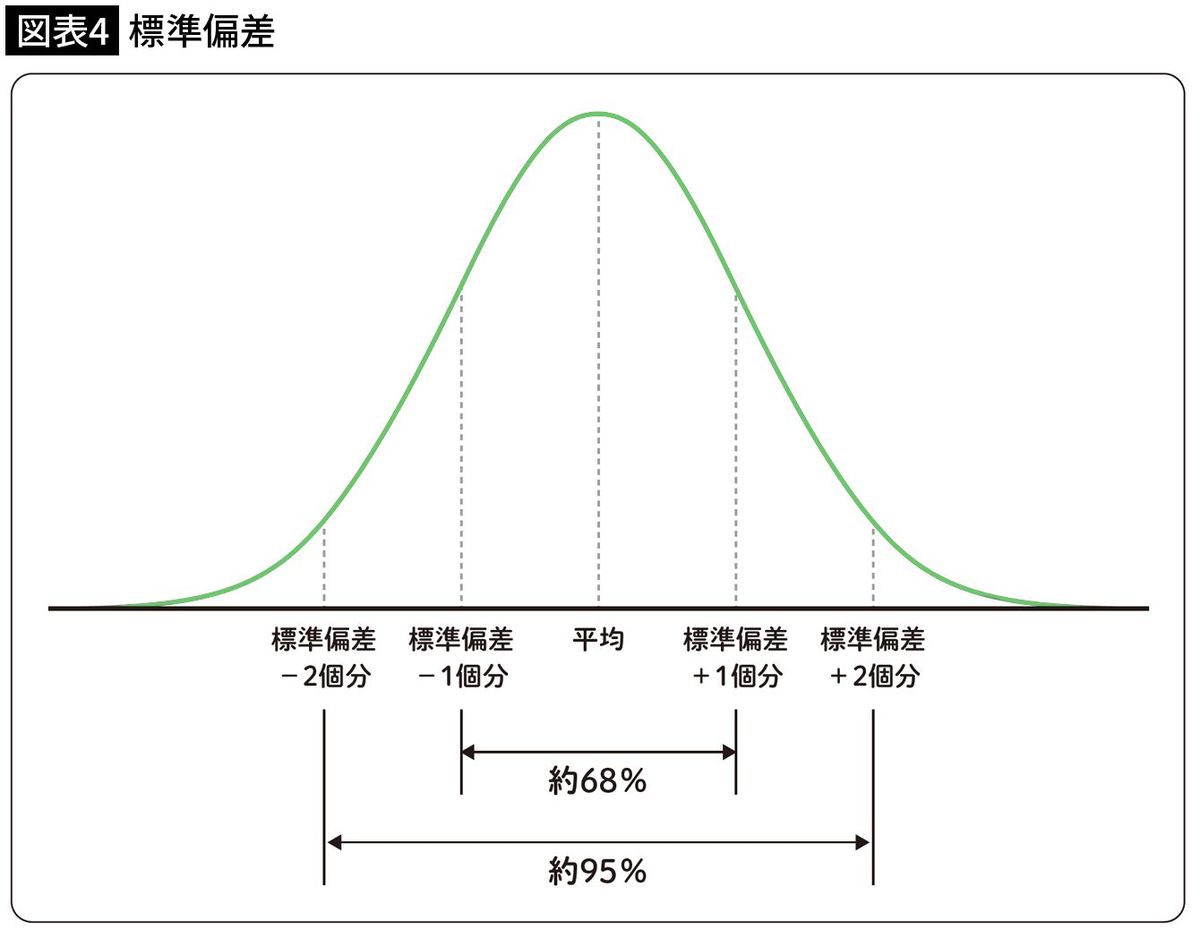
自分の得点はどれくらいの位置にいるのかを知るのに適しているのが標準偏差です。
平均を中心に、±1個分の標準偏差で全体の68%、±2個分の標準偏差で全体の95%を占めます。
もし標準偏差が5点なら、70点は標準偏差-2個分、すなわち下位5%に該当するので、先にあげたわたしの得点では絶望的だとわかります(図表4)。
ちなみに試験で必ず求められる偏差値は「(得点-平均点)÷標準偏差×10+50」で求まります。
わたしの場合、
となります。
模試を受けると大半の場合は偏差値もわかりますが、あれは全体における自分の学力の傾向を示していたのです。
偏差値を求めれば、仮に1回目の模試と2回目の模試が同じ得点でも、平均点が変動していれば偏差値も変動し、自分の学力がどれほどなのかを判断するのに役立ちます。
----------
データサイエンティスト
1984年生まれ。龍谷大学法学部卒業後、データサイエンスの重要性を痛感し、多摩大学大学院で“学び直し”。その後、デジタルマーケティング、消費者インサイト等の業務に携わり、現在は事業会社でマーケティング全般を担当している。政治、経済、文化など、さまざまなデータをデジタル化し、分析・予測することを得意とし、テレビ、ラジオ、新聞、雑誌にも登場している。主な著書に『人は悪魔に熱狂する 悪と欲望の行動経済学』『データサイエンス「超」入門 嘘をウソと見抜けなければ、データを扱うのは難しい』(以上、毎日新聞出版)、『なぜ「つい買ってしまう」のか? 「人を動かす隠れた心理」の見つけ方』『誤解だらけの人工知能』(以上、光文社)、『データから真実を読み解くスキル』(日経BP)など。
----------
(データサイエンティスト 松本 健太郎)
外部リンク

この記事に関連するニュース
-
平均手取り「30万円」より悲惨…日本でどんどん露わになる「恐ろしい経済格差」
THE GOLD ONLINE(ゴールドオンライン) / 2024年7月17日 10時15分
-
婚活で「年収600万円」の女性と出会いました。2人で「年収1200万円」ですが、結婚後は“パワーカップル”として暮らしていけますか? 将来的には子どもも考えています
ファイナンシャルフィールド / 2024年7月17日 4時30分
-
中学受験「偏差値50の中高一貫校」は「地方トップ校」とほぼ同レベル…高学歴親ほど要注意"偏差値の落とし穴"
プレジデントオンライン / 2024年7月13日 9時15分
-
〈平均給与458万円〉より「もっと厳しい」…所得が下がった「日本人の現状」
THE GOLD ONLINE(ゴールドオンライン) / 2024年7月8日 18時30分
-
現在のビットコイン価格は「高すぎ」か、実は「割安」か...オンチェーンデータから見る「本当の買い時」
ニューズウィーク日本版 / 2024年7月3日 17時41分
ランキング
-
1全国給油所、29年連続減少 2.7万カ所、需要縮小
共同通信 / 2024年7月29日 18時23分
-
2MSに補償請求を検討と報道 米デルタ航空、システム障害で
共同通信 / 2024年7月30日 8時37分
-
3日本一短い航空路線が廃止 「たった10分」のフライトがもたらしてきたもの
ITmedia ビジネスオンライン / 2024年7月30日 6時20分
-
4タリーズコーヒー、創業記念にこだわり「バニラアフォガートシェイク」発売 限定ボトルもかわいい
J-CASTニュース / 2024年7月29日 7時0分
-
5NTTグループ、「カスハラに対する基本方針」 発表 悪質な場合は法的措置も
ITmedia ビジネスオンライン / 2024年7月29日 14時51分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください






