

Meteor Lakeを凌駕する性能のQualcomm「Oryon」 Hot Chips 2024で注目を浴びたオモシロCPU
ASCII.jp / 2024年9月9日 12時0分

今年も8月25日からHot Chips 2024が開催された。プログラムの内容は公式サイトで確認できる。この中で言えば、インテルのLunar LakeとAMDのInstinct MI300X/Versal AI Edge Gen2、それとZen 5コアの話は残念ながらあまり新しい情報はなかった。
Xeon 6 SoCに関しては前回の最後で説明しているので割愛するが、それ以外にPCなどとは直接関係ないが、いろいろおもしろいプロセッサーの説明があったので、今回からしばらくこれらを紹介していく。

Nuviaを買収して入手した QualcommのPC向けCPU「Oryon」
最初はQualcommのOryon(オライオン)である。言うまでもなくチップセットのSnapdragon X Eliteに搭載されているCPUだ。このOryon、もともとの開発は米Nuviaであるが、同社は2021年1月にQualcommに買収された。
そもそもなぜQualcommはNuviaを買収してOryonを手に入れたかったのか? という話をすると長いのだが、簡単にまとめるとQualcommはArmのIPライセンスを受けてこれを自社の製品に利用するとともに、ハイエンド向けに関してはアーキテクチャーライセンスを受けて自社で製品開発をしていた。
2008年のScorpio、2012年のKrait(クライト)、2015年のKryo(クライオ)がその主要なコアである。最初のScorpio(スコーピオ)は2007年のFall Processor Forumで内部構造が紹介された。
ただ2015年のKryoが最後の独自アーキテクチャーであり、その後QualcommはKrait/Kryoの名前を使いながら再びArmのCPU IPを利用したラインナップに戻っている。製品構成を見ると以下のようになる。
複数あるのは時期が異なるためで、例えば2021年にリリースされたSnapdragon 8 Gen 1は、Kryo Prime(Cortex-X2)×1+Kryo Gold(Cortex-A710)×3+Kryo Silver(Cortex-A510)×4の構成だが、2023年のSnapdragon 8 Gen2ではこれがKryo Prime(Cortex-X3)×1+Kryo Gold(Cortex-A715)×2+Kryo Gold(Cortex-A710)×2+Kryo Silver(Cortex-A510)×3になっている。要するにKryoはQualcommのCPUブランドであり、特定のアーキテクチャーを指したものではない。
そんなQualcommであるが、独自路線を止めてArmのCPU IPを利用したものの、トップエンド製品に関してAppleのコアに性能で敵わなかったのがかなり不満だったらしい。だからといって、新規にCPUのアーキテクチャーを開発するには圧倒的に時間が足りない。一般論としてCPUアーキテクチャーをスクラッチから開発すると5~6年を要する。それを待てないからこそ、QualcommはNuviaを買収したわけだ。
ただこれはArmのお気に召すところではなく、2022年にArmはQualcommに対して、Nuviaの設計を利用するのはライセンス違反になるので、Nuviaの設計を破棄するように求めた。
少し話が複雑になるが、NuviaはArmのアーキテクチャーライセンスとテクノロジーライセンスを保有しており、このライセンスの元で独自のOryonコアを開発したのだが、Armはこのライセンスの期限が2022年3月に失効しており、そもそもこのライセンスは他社に譲渡不可能であるので、Qualcommがこの期限後にOryonコアを利用するのはライセンス違反になる、と主張している。
これに対しQualcommは今年4月18日にArmを反訴している。この反訴でQualcommが主張した文言は以下のとおり。
「ArmはQualcommが支払ったライセンス料の対価となる納品物を意図的に留保、QualcommがArmの納品不履行について書面で通知した際、これらの納品物の存在を偽って伝えるとともに、Qualcommが問題の納品物を取得する契約上の権利を行使しようとした場合、Qualcommへのライセンス供与を終了すると脅迫することで、QualcommのCPU設計における技術的飛躍を阻害しようとした」
「Armは、Qualcommの保有するアーキテクチャーライセンスにはQualcommがNuviaベースの技術を利用できる権利はないという口実で、Qualcommが権利を持つ成果物(=NuviaのコアのIP)の利用を意図的に妨害した」
「Armは納品の不履行を是正することはなく、Qualcommは製品の設計と検証に不必要な追加リソースを費やすことになった」
結果、今年のCOMPUTEXにおける基調講演でQualcommは大々的にAIPCをデモしたにも関わらず、そこにArmのCEOが参加することはなかったし、逆にArmの基調講演の中でQualcommという言葉が出てくることもなかった。
もうお互いに訴えあっている状況なので、どちらの主張が正しいか議論するのはあまり意味がなく、法廷で決着がつくか、もししくは法定外和解の結末が出てくるのを待つしかないのだが、Oryonというのはそういういわく付きのCPUコアなのである。
OryonのROBエントリー数は600以上! インテルのSkymontに負けない規模の構成
そんなOryonだが、基本は4コア単位のクラスターでの構成になるようで、2次キャッシュは4コアで共有になる。

それぞれのコアの構成は下の画像のとおり。まずフロントエンドだが、8命令/サイクルのデコーダーと192KBのL1 I-Cache、強力な分岐予測と50ものRSP(Return Stack Predictor)と、インテルのSkymontに負けない規模の構成になっていることがここから大まかに見えてくる。

実際の構成を見ると、ROBのエントリー数が600以上(実際は650以上)というすさまじい数になっており、一体どれだけの数の命令をインフライト状態で保持しているのか? という疑問が湧いてくる量だ。
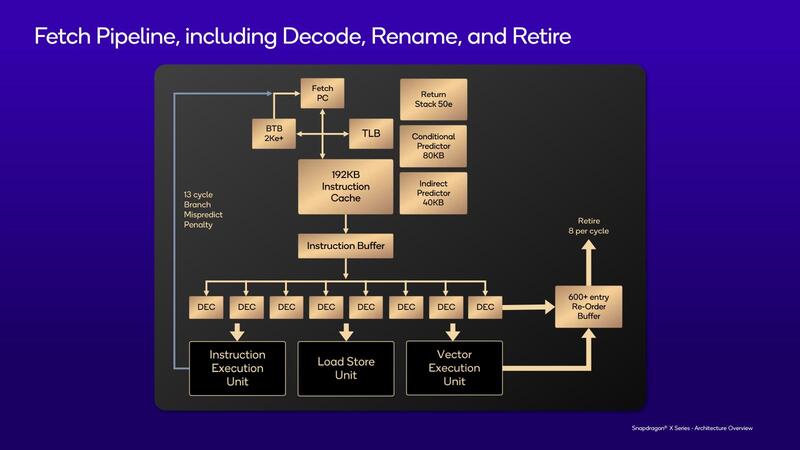
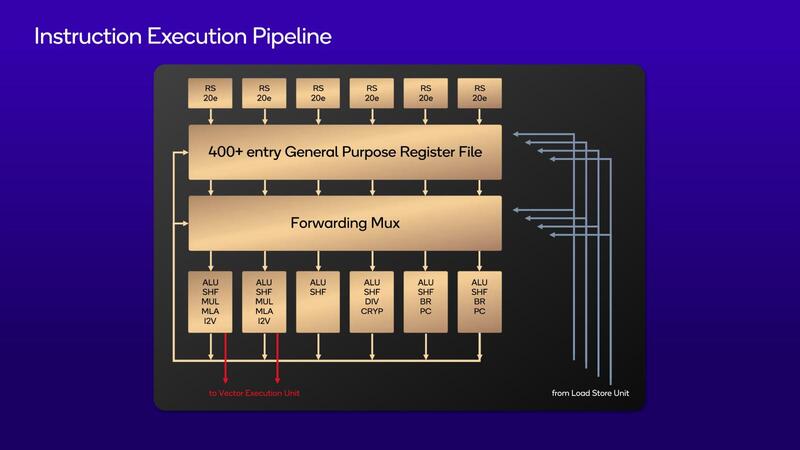
一方、バックエンドの方はALUこそ6命令/サイクルだが、分岐命令を2命令/サイクル実行でき、またレジスターファイルをALU/FPともに400以上というから、こちらも相当の命令をインフライト状態で保持できることがわかる。

またFPUに関して、SVE/SVE2には未サポートであるが、NEONを最大4つ実行できるというあたりはかなり強力な構成である。もう少し詳細にみると、Integerの側は下の画像のように6つのIssue portが用意され、おのおの20エントリーのRS(Reservation Station)が付く格好だ。左の2つのユニットのみVector Unitへのリンクがあるが、これはI2V(Integer to Vector)用と思われる。
同様にFP側は、Issue Portは4つだが、おのおの128bit幅である。ほぼ対称型(FDIV/IDIV/Cryptography/V2Iのみ違っている)なので、例えばもし将来それが必要と判断されたらSVE2を実装することは可能で、ただ現状では不要と判断されたように見える。RSもおのおの48エントリーなのでかなり多い。
全体として見ると、構成そのものはそれこそSkymontやCortex-X4にはややおよばず、CrestmontやCortex-X3などに近い。ただしCrestmontやCortex-X3に比べると、インフライトの形で保持できる命令数が明らかに増えているように思える。おそらく8つのALUをそこそこの利用率で使うより、6つのALUをギリギリまで使い切る方が効率が良いと判断したのであろう。
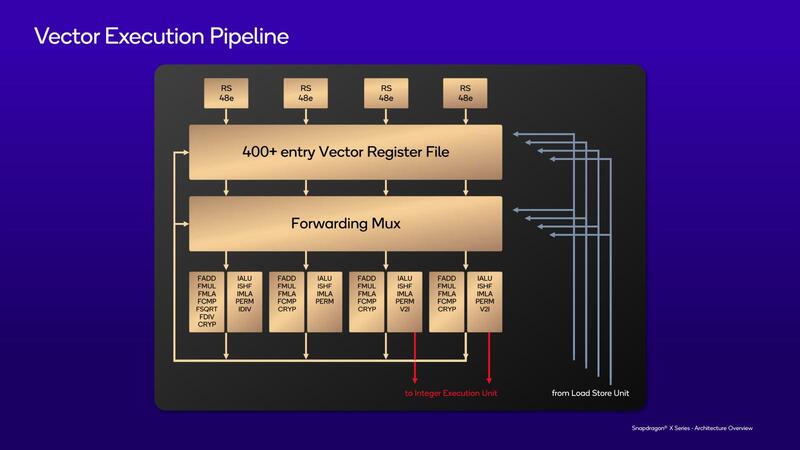
これを支えるロード/ストアーユニットであるが、L1 D-Cacheは96KB。ロード/ストアーユニットは4基用意されている。またL1 D-TLBが224エントリーというのは、これまでのQualcommのプロセッサーと比較すると少し多いが、これはターゲットがスマートフォンからPCに変わり、より大量のデータを扱うようになることへの対策なのかもしれない。

L1はインストラクション/データともに64Bytes/サイクルの帯域になり、L1/L2も64Bytes/サイクル、L2の先は32Bytes/サイクルになっている。L2は12MBと、これもQualcommのプロセッサーとしては大容量だが、4コアで共有(つまりコアあたり3MB)と考えると妥当な線なのかもしれない。

メモリー管理周りは、VMを多用することを考えてか、けっこう重厚な構成である。Table Walkを同時に複数発行できる、というあたりもスマートフォン向けというよりはPC向けのCPUという感じだ。興味深いのは、メモリーアクセスのGranularityが16bitなことで、このあたりはスマートフォン向けだと感じる。


※お詫びと訂正:記事初出時、命令の名称に誤りがありました。記事を訂正してお詫びします。(2024年9月11日)
シングルスレッド性能はMeteor LakeとEmerald Rapidsを凌駕
最後に、Qualcommが示したベンチマーク結果が下の画像だ。
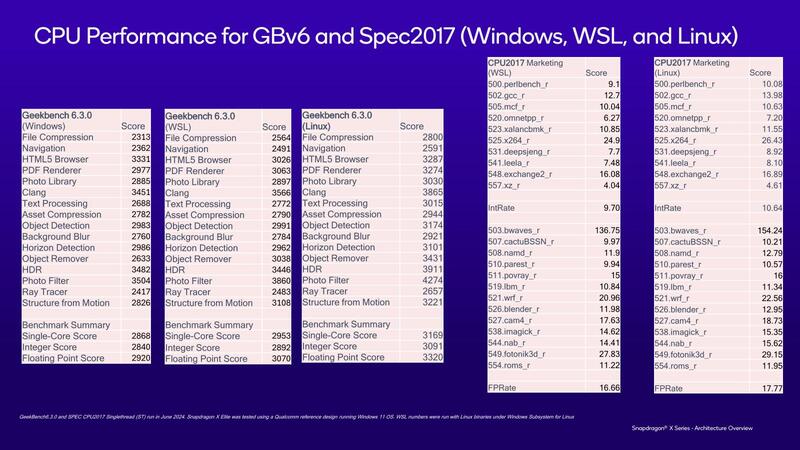
これ、比較がすごく難しいというか、比較対象がないのだが、例えばGeekBench 6.3.0ではMicrosoft Surface Laptop 6 for Business(Core Ultra 7 165H搭載)の結果と比較してみると、下表のようになり、確かにシングルスレッド性能はMeteor Lakeを凌駕するものになっている。
もっと難しいのがSPEC CPU 2017の結果で、公式のリザルトデータベースはサーバー向けCPUでの結果ばかりで比較が非常に難しい。一応Emerald Rapidsこと第5世代Gen Xeon ScalableのXeon Platinum 8592V(60コア/120スレッド)を使った結果と比較してみると、下表のようになる。
公平な比較かどうかは議論が残るが、PコアベースのEmerald Rapidsを上回るシングルスレッド性能を出しているとは言えるわけで、確かに言うだけのことはある結果になっている。
現状Snapdragon X EliteはCPU性能よりもむしろGPU性能の方がいろいろ足りないなどと言われているが、なるほどCPUに関しては相応に自信があることを物語る結果になっているのは興味深い。問題はここからQualcommはどこまで継続的に内部を改良して性能を上げていけるか、というあたりだろう。
当然Armとの訴訟合戦もここには絡んでくるので、それもあってか今回特に今後のロードマップなどは示されなかった。インテルやAMDが怖いのは、毎年のよにアーキテクチャーを改良して性能を上げてくる点で、Qualcommがこれに負けずにOryonを今後も改良し続けられるかどうかがポイントになりそうだ。

この記事に関連するニュース
-
クアルコムとガーミン、次世代デジタルコックピット共同開発へ…CES 2025
レスポンス / 2025年1月7日 20時30分
-
Intelが「Core Ultraプロセッサ(シリーズ2)」のラインアップを一気に拡大 ノートPC向けを中心にデスクトップPC向けや組み込み用も
ITmedia PC USER / 2025年1月6日 23時5分
-
インテルがCore Ultra 200HX/H/Uシリーズを発表、285HXの性能は前世代から最大41%向上
ASCII.jp / 2025年1月6日 23時0分
-
Intel×AMD×Qualcomm対決! 3プラットフォームの14型AI PC(Copilot+ PC)をテスト 比べて分かった違い
ITmedia PC USER / 2024年12月27日 12時0分
-
Intel×AMD×Qualcomm対決! 3プラットフォームの14型AI PC(Copilot+ PC)を横並びで比べてみた
ITmedia PC USER / 2024年12月24日 12時0分
ランキング
-
12023年に急逝した五彩緋夏さんの親友、“2年前の写ルンです”を現像……緋夏さんとのお宝ショットに「この写真が見れてよかった」と大きな反響
ねとらぼ / 2025年1月13日 12時45分
-
2「神ゲー」日本からの声高く翻訳後の日本売上7倍に、“日本人に何故か熱い注目あびたため”日本語実装のインディーSRPG―「実際は、賭けだった」語られる裏側
Game*Spark / 2025年1月11日 18時45分
-
3IIJmio、mineo、NUROモバイル、イオンモバイルのキャンペーンまとめ【1月15日最新版】 110円スマホや高額ポイント還元あり
ITmedia Mobile / 2025年1月15日 10時34分
-
4セザンヌの“700円福袋”を開封したら…… 予想以上の開封結果に驚きの声「太っ腹すぎる!」「プチプラでも優秀」
ねとらぼ / 2025年1月14日 19時30分
-
5平子理沙、LA大火災で長年住んだ“豪邸全焼”……思い出あふれる街全滅に「とても悲しくショックを受けています」
ねとらぼ / 2025年1月15日 11時45分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





