

AI向けシステムの課題は電力とメモリーの膨大な消費量 IEDM 2024レポート
ASCII.jp / 2024年12月30日 12時0分

12月7日~11日にかけ、サンフランシスコでIEDM(International Electron Device Meeting) 2024が開催された。前回に続いてこの内容について取り上げたい。
今年のテーマは"Shaping Tomorrow's Semiconductor Technology"となっており、実際次世代向けのプロセスに関する話題が多く発表されている。
今回は、招待講演である21-6の"Tomorrow's Modular & Scalable Compute Systems"の内容をご紹介したい。講演者はAleks Aleksov博士(Principal Engineer, Semiconductor Packaging and Systems Integration Research)ら4人となっている。
AI向けシステムが抱える課題は 膨大な消費電力とメモリーの使用量
講演はまず市場概観から。2014年以降のAI関連の投資がすさまじいという話はこれまでもあちこちで言われている話である。
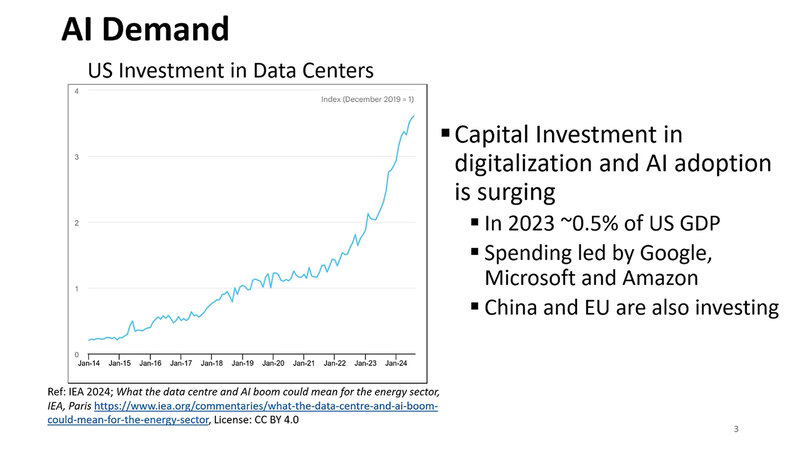
この結果として市場に急速にAI向けのシステムが導入されるようになったことで消費電力量が急増しているわけだが、現在の伸びからの推定で言うと、2030年末にはアメリカの消費電力量の16%を占める、という衝撃的な推定がなされている。
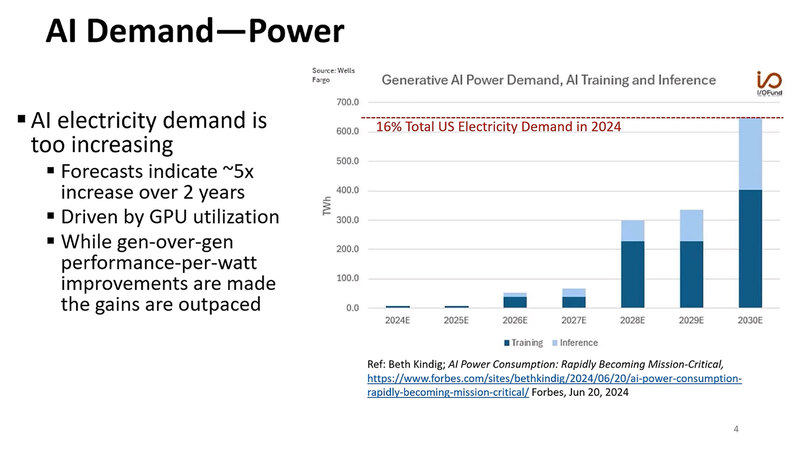
興味深いのは、現状はほとんどがAIのトレーニング向けで占められている電力消費が、今後は次第に推論もバカにならなくなると見られていることだ。LLM(大規模言語モデル)の推論は結構な消費電力を必要とするのは事実である。
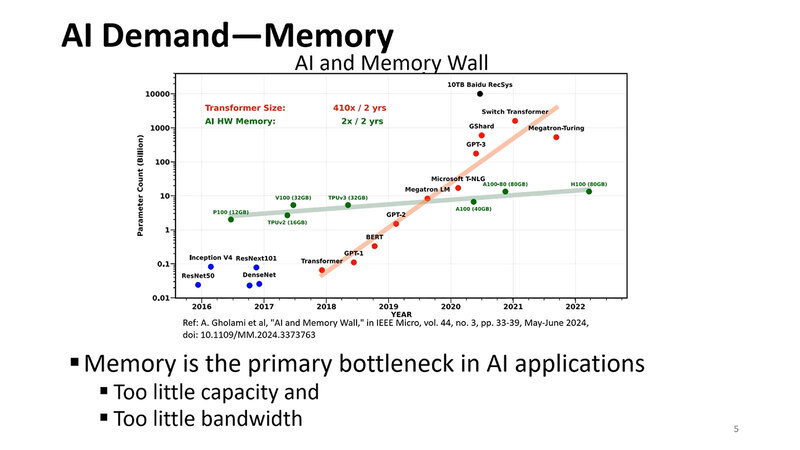
もう1つ問題になっているのがメモリーの問題である。メモリー容量は2年で2倍という、これはこれで猛烈なペースでの増加になっているが、特にLLMの方は2年で410倍という、尋常ではない勢いでネットワークが拡大しており、この結果メモリー容量とメモリー帯域の両方が足りない現象が起きている。
このメモリーに絡んでもう1つあるのがインターコネクトの能力不足である。単にチップレットだけでなく、昨今はモジュールを複数接続してキャビネットに収め、そのキャビネットを集積したラック同士をさらに接続というようにスケールアウトの方向にどんどん展開しつつある。
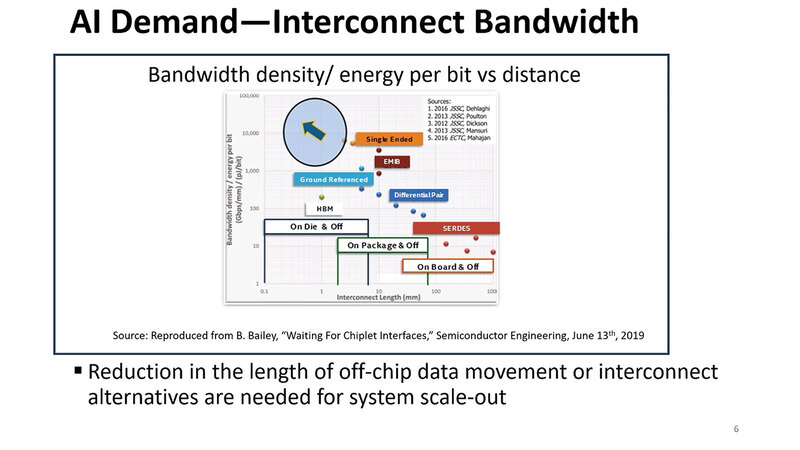
また、オンダイで集積できるメモリーの量に限界がある以上、ダイの外にメモリーを集積する形になるため、このメモリーとの接続もまた問題である。余談だが上のグラフ、縦軸が単位距離・単位消費電力当たりの転送速度という複雑なものになっているのがおもしろい。
連載801回で少し触れたが、UCIeはStandard Packageで1mm幅に56対、Advanced Packageで330対の信号を通せる。配線密度が上がれば信号速度を落としても帯域は確保しやすいわけで、このあたりもバーターになっている。結果、縦軸がGbps/mmをpJ/bitで割る、という形になっている。
ちなみにスライドの一番下にあるように、データの移動をどうやって減らすかがキーであり、これを突き進めるとIn-Memory Computingになるわけだが、現状では汎用性がないので、なにかしら汎用プロセッサーと組み合わせないと処理が難しい。
さらに、In-Memory Computingといっても1つのダイに収められるComputation Unitとメモリーの量には限界があるから、スケールアウトを考えると結局なんらかのインターコネクトが必要になるので、結果としてIn-Memory Computingだけで解決するわけではない、というあたりが難しいところである。
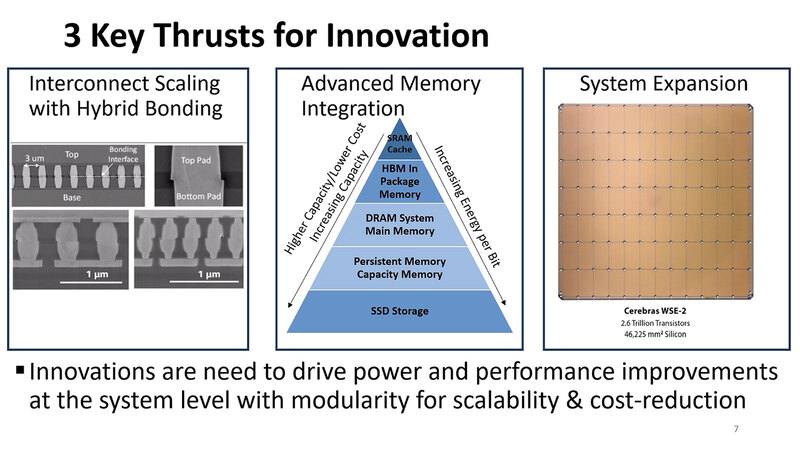
コスト面での課題は残るが 次世代のインターコネクトとして有望なHybrid Bonding
こうした問題を3つに集約して、それぞれ論じるとする。まずインターコネクトの話。ここで論じているのはHybrid Bondingである。
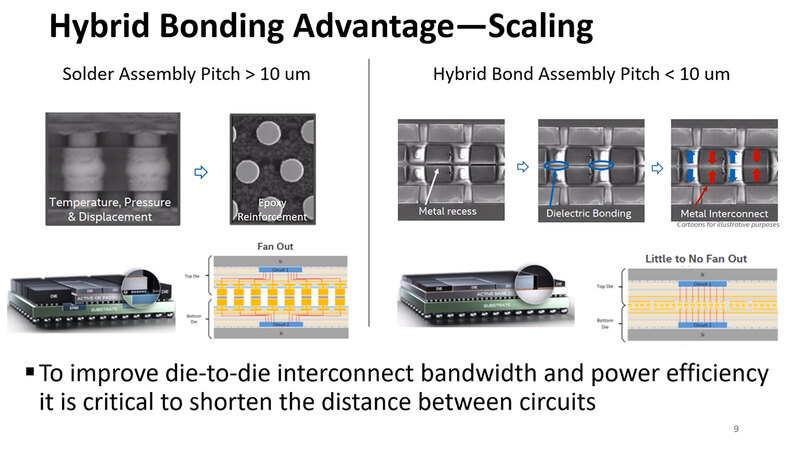
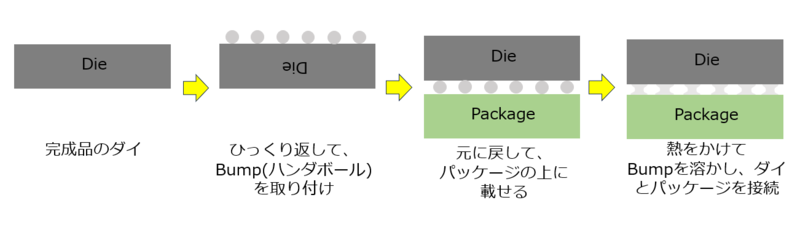
一般論であるが、ダイを基板の接続、あるいはダイ同士の接続は基本Bumpと呼ばれるハンダのボールを利用してきた。下図はこのBumpを利用する場合の基本的な接続手順である。長らく利用されてきた実績ある方法である。
最近は、特にシリコン・インターポーザーを利用する場合などには、ハンダボールの直径を非常に小さくしたMicroBumpと呼ばれるものも利用されているが、それでも以下の問題がある。
- Bumpを使う限り、温度(と圧力)を掛けた時にハンダが広がる関係で、Pitch(Bumpの間隔)を10μm未満にするのが極めて難しい。
- Bumpは基本ハンダ(さすがに最近は鉛は使われず、スズと銅、銀の合金などが利用されることが多いが、これも用途に応じてさまざまなものがある)で構成されるが、確実な接続が優先されることもあって、電気抵抗などが多い。
- Bumpを経由する場合は、基本チップの外に信号を出すという扱いになるので、PHYというほど大げさではないにしても出力用の回路(Fan Out)が必要になり、これが通信に利用する消費電力の増加につながる(あと非常にごくわずかではあるが、レイテンシー増加につながる)。
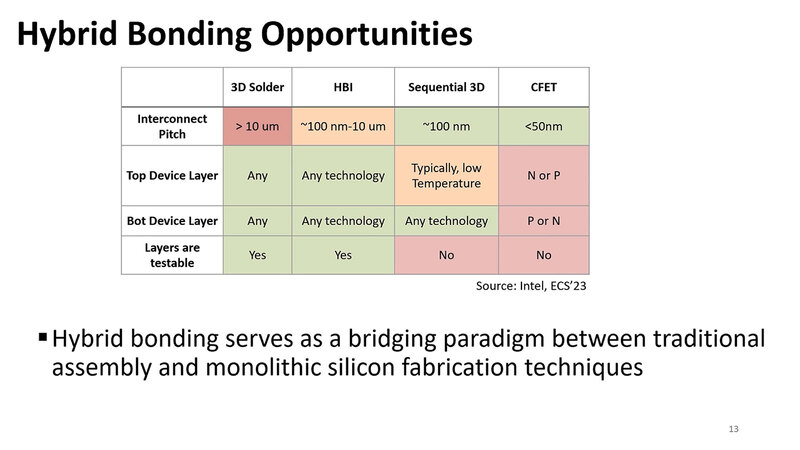
これを解決するのがHybrid Bondingと呼ばれる技法で、要するにBumpを介さずに直接2つのダイ(あるいはダイとパッケージ)を接続する方法である。もっとも現状ダイとパッケージの接続はまだ難しく、ダイとダイの3次元積層に限られている。TSMCのSoIC、あるいはインテルのFoveros DirectがこのHybrid Bondingに該当する。メリットはBumpの逆で、以下のように高速化や省電力化には欠かせない特徴を兼ね備えている。
- 接合時にBumpが広がらないので、ピッチを10μm未満にすることも十分可能。
- 基本は銅と銅が直接触れ合う形になり、余分な抵抗が減る。これにより消費電力と、寄生容量に起因するレイテンシーを最小限に抑えられる。
- 基本はFan Outは不要(実際には若干保護回路が入る)
実際このHybrid Bondingを利用した場合、まず接続に必要となる面積は30分の1、接続に要する消費電力は10分の1であり、レイテンシーは8分の1になるというのがここでの説明である。ほとんどモノリシック(つまりマルチダイ構成を使わない1ダイ構成)と変わらない特性を維持できるとする。

では欠点は? というと、まずはコストである。TSMCのSoICや、これを利用したAMDの3D V-Cacheが好例だが、Hybrid Bondingはファンデルワールス力を利用する。分子間力を利用しての接続だが、このためには接続面が非常に平滑でないといけない。
したがって接続面をCMP(Chemical/Mechanical Polishing:研磨剤などを使ってキレイに磨く処理)やRinse(CMPの後で、表面を整える処理)などが必要となる。また、2つのダイの接続面が正しい位置関係にないと、うまく信号が伝わらないことになる。このための位置合わせの精度は1μm未満でないといけないわけで、これに猛烈な手間(とコスト)が掛かる。
加えて言うと、検査もまた大変である。Bumpの場合は10μm程度だから、X線CTスキャナーで検査することで、正しくBumpの接続ができているか確認できるのだが、Hybrid BondingはギリギリNano-CT(1μm未満の解像度を持つX線CTスキャナー)が必要であり、その下はTEM(透過型電子顕微鏡)などの領域になってしまう。
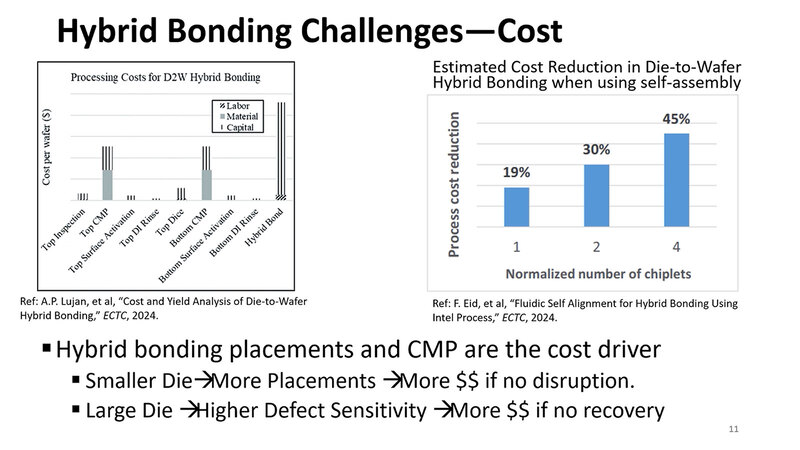
左の写真のように、「接続できているようでつながってない」とか「中央はつながっているけど両端がつながってない(これは少しの衝撃や歪みなどで剥がれる可能性がある)」などをチェックしようとすると、猛烈な手間が掛かる。
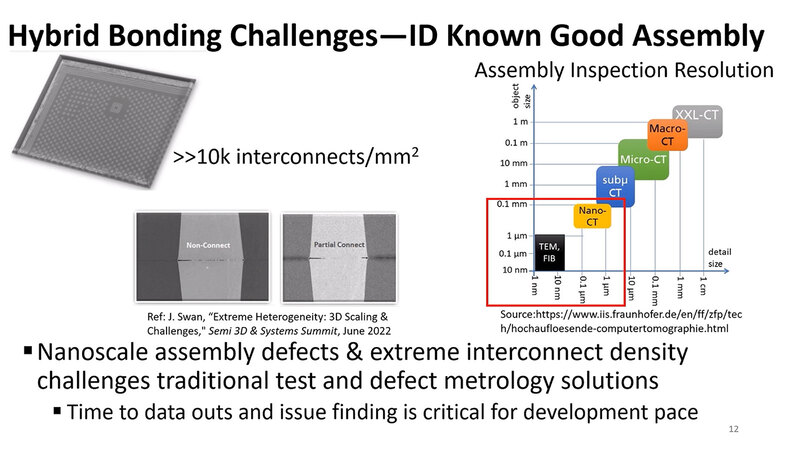
このようにいろいろと課題はあるものの、Hybrid Bondingは現時点では次世代のダイ間接続のインターコネクトとして非常に有望であるとし、複数チップを積層するようなケースで利用できるというのが1つ目のまとめである。
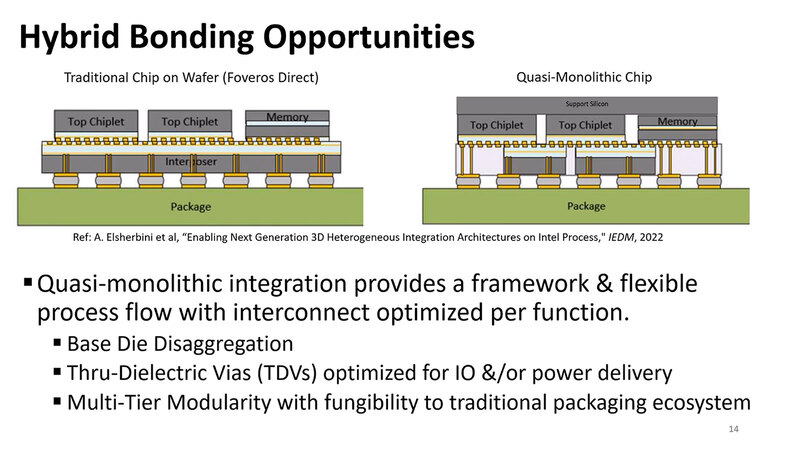
チップの上に直接DRAMを積層することで メモリー帯域とメモリー容量問題の解決を図る
2つ目がメモリーの問題。下の画像が従来のメモリー構成であり、Ponte Vecchioなど4階層のメモリーを搭載しているわけだが、そのPonte Vecchioですらメモリー帯域と容量が足りていないので、もう少し別の方法を考える必要がある。
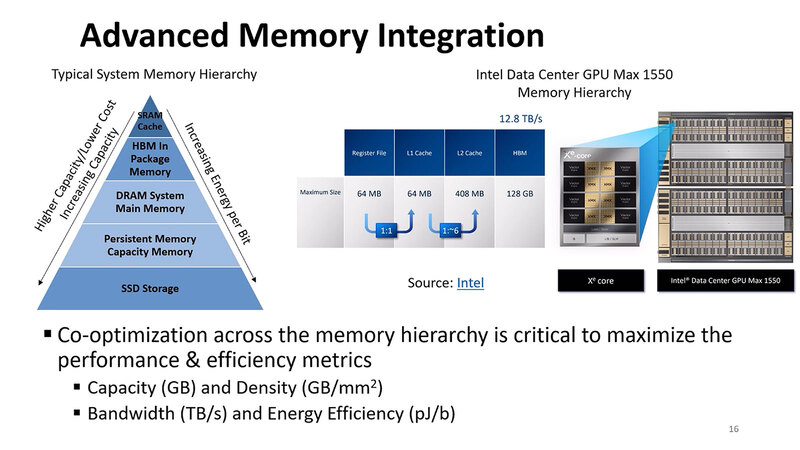
そのPonte Vecchioの後に出てきたAI向けプロセッサーが、いろいろな意味で限界までメモリー量とメモリー帯域を引き上げているのを見れば、この方向でもう少し頑張るしかないわけだ。
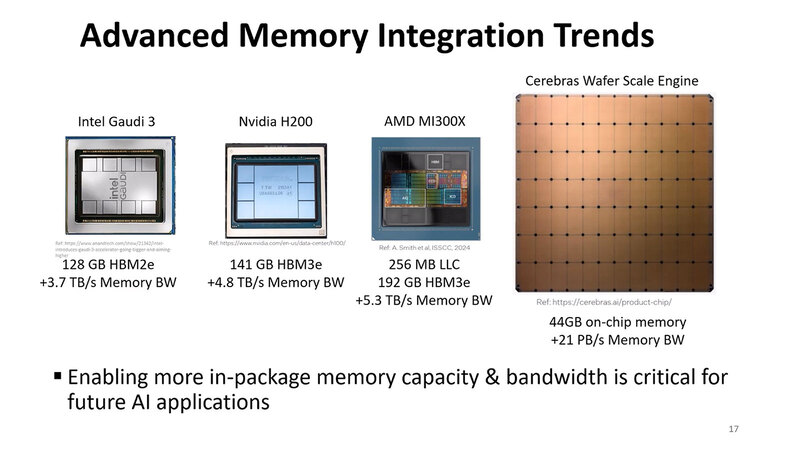
一番考えやすいのは、さらにHBMのスタックを積み上げる(=容量を増やす)とともに信号を高速化するなどで帯域を引き上げることだが、これは言ってみれば小手先の改良であって、大きく性能を改善する助けにはならない。

この方面に関して明確な解が示されているわけではないのだが、1つのアイディアとして示されたのがStacked Embedded DRAMである。要するにチップの上に直接DRAMを積層するというアイディアだ。
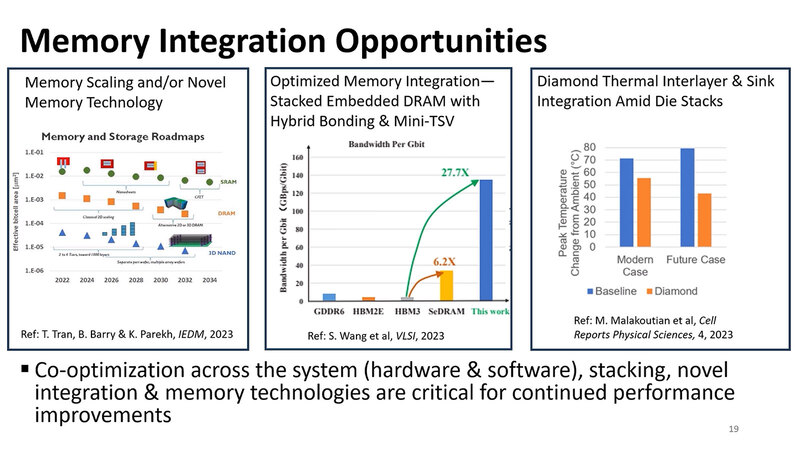
実はこれ、連載798回で取り上げたMN-Core 2の後継であるMN-Core L1000で実装されようとしている。

要するにHBMの消費電力が多いのは、インターポーザー経由になっている(つまり先の話で言えばFan Outでの接続になる)部分が少なからず関係する。つまり、DRAMをHybrid Bondingで接続するようにすれば、信号速度を控えめにしても帯域が確保しやすく(これは配線の本数を大幅に増やせるから)、またHybrid Bondingだからインターコネクトの電力も低く抑えられる。
チップの上のDRAM積層に関しては、MN-Coreのアーキテクトである牧野淳一郎博士のXへのポストがなかなか興味深い。
DRAM 3 次元実装についての牧野の https://t.co/kvYWywQzrq 19年前の文章
— Jun Makino (@jun_makino) December 11, 2024
これは、Hybrid Bondingを使う限り熱抵抗が大幅に減るので、DRAMをチップの上に載せても放熱に問題が出にくい、という話である。理屈はわかるのだが、それはロジックダイの発熱が穏当なものの場合だろう。
これがH200や、身近なところではCore Ultra 9でもいいのだが、要するに90度以上で連続動作するような状態ではDRAMの記憶保持時間が相当短くなりそうで心配である。したがってこの手法は、ロジックダイ側の動作周波数を相当低く抑えるか、液冷などで強制的に50~60度に抑え込む必要がありそうではあるが、1つの可能性ではあるかと思う。
コストを度外視すればSRAMを大量に3D実装という選択肢もありそうだが、これは本当にコストが論外になりそうではある。
インターコネクト問題は光インターコネクトで解決できる
最後がシステムインテグレーションの話である。現状CelebrasのWSEなりTeslaのDojoなりが、製造できる最大のチップということになるが、これでもまだ性能が足りない以上、当然これを複数利用したシステムを構築することになる。

そういうケースでは、コストの面からモジュラリティを利用するのが得策というのが現在のトレンド、というのはMI300Xが一番適切な気がする。

ただモジュラリティを追求しようとすると、またもやインターコネクトの問題が再現することになる。これに関する解の1つが、連載801回でも説明した光インターコネクトである。
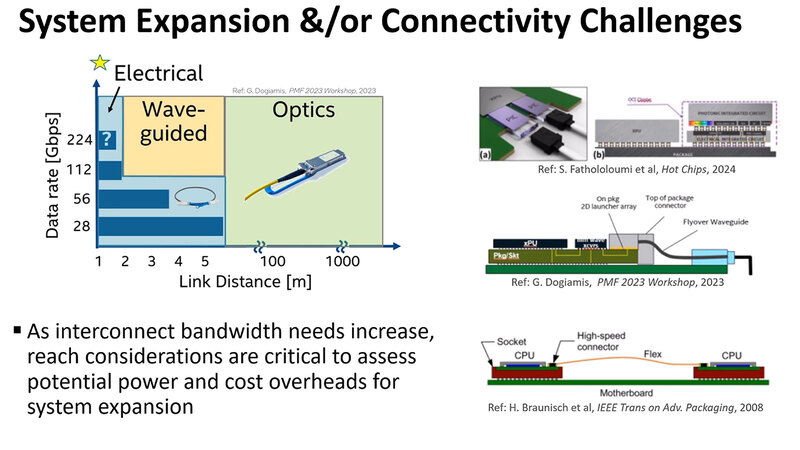
チップレット同士の接続にはやや大げさすぎるが、モジュール同士、あるいは同一ラック内のシャーシ同士など「小規模な」ラック間接続にはちょうど適切な解と言える。
そこで提案としては、微細なところはそれこそ冒頭に説明したHybrid Bonding、大きなダイ同士の接続は引き続きインターポーザーを使った2.5D接続、その外には光インターコネクトという感じで役割分担させるのが現実的と説明する。
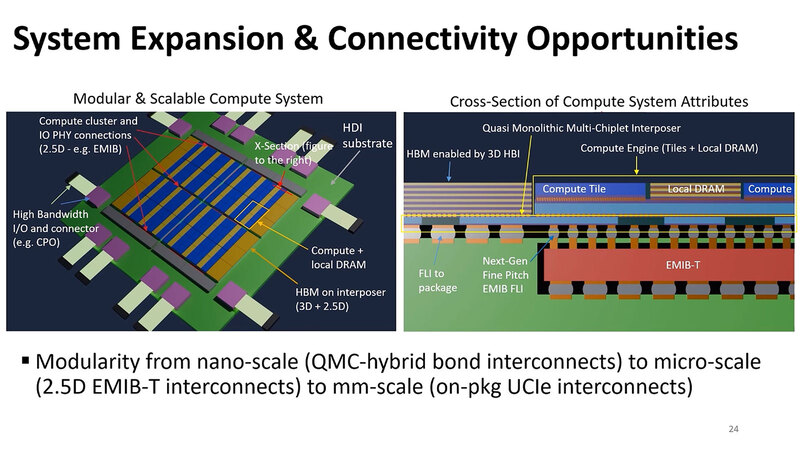
さらに将来的には、これをさらにスケールアウト的につなぐとか、Panel Fan Out(現在の300mmウェハーベースではなく、600mm×600mmのパネルベースでパッケージを製造することを前提に、このパネルベースでシステムを構築するという話)などを示した。
今回の話、インテル的にはHybrid Bondingに関してはいろいろ開発が進んでいることもあってか、かなり具体的なリアリティのある話だったのに対し、メモリーやシステムインテグレーションに関してはまだ夢物語に近いレベルの内容も含むものだったのは、まだこのあたりは研究や開発の余地があることの裏返しかと思われる。
とはいえ、チップだけでなくこうしたパッケージ側もなんとかしないと、消費電力や製造コストがとんでもないことになってしまう、という危機感は間違いなく感じられるものだった。
問題は、ではこのメモリーやシステムインテグレーションが現実に提供されたとして、それは記事冒頭で提示した消費電力とメモリー容量の問題解決に十分だろうか? というあたりだろう。残念ながらその解は今回示されなかった。

この記事に関連するニュース
-
ウエスタンデジタルの新型PCI Express 4.0 SSD「WD_BLACK SN7100」を試す パフォーマンスは良好でノートPCへの組み込みにお勧め
ITmedia PC USER / 2025年2月5日 17時45分
-
銅配線をルテニウム配線に変えると抵抗を25%削減できる IEDM 2024レポート
ASCII.jp / 2025年2月3日 12時0分
-
不足しがちなポータブルゲーミングPCの容量もこれでOK! ネクストレージの内蔵SSDが最大27%お得に買える
ITmedia PC USER / 2025年1月27日 13時55分
-
ミドルレンジの新GPU「Intel Arc B570」を試して分かったこと ゲーミング/動画処理の入門にお勧めだがネックは?
ITmedia PC USER / 2025年1月17日 0時0分
-
Crucial、メモリとストレージのポートフォリオを拡大コンシューマー向け製品のパフォーマンスが大幅に向上
PR TIMES / 2025年1月14日 15時15分
ランキング
-
1X、「コミュニティ」の投稿が誰にでも表示される仕様変更 ユーザー当惑「最悪のアプデ」
ITmedia NEWS / 2025年2月4日 19時13分
-
2現役の情シスが考える、KDDIのビジネスPC向け“月額費用なし”データ使い放題サービス「ConnectIN」の強み
ITmedia PC USER / 2025年2月4日 12時40分
-
3ラップの空箱は捨てないで! “目からウロコ”な活用法が240万再生 「天才だ…」【リメイク】
ねとらぼ / 2025年2月4日 7時30分
-
4ニットの収納“生地が伸びる問題”を解決 目からウロコの裏ワザに「その手は思いつかなかった」「やってみます」
ねとらぼ / 2025年2月4日 7時30分
-
5情報セキュリティ10大脅威2025年版が公開 新たに加わった2つの脅威に注目
ITmedia エンタープライズ / 2025年2月4日 7時15分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





