

要求にあわせて構成を変更できるSynopsysのARCシリーズ AIプロセッサーの昨今
ASCII.jp / 2023年5月1日 12時0分

1ヵ月ぶりのAIプロセッサー連載、今回はSynopsysのARC NPUを取り上げたい。SynosysというのはCadenceと並ぶ2大EDAベンダー(*1)の片割れである。

EDA(Electronic Design Automation)とは要するにLSIの設計支援ツールであるが、昔はそれこそ配線CADを提供するだけのベンダーだったのが、プロセス微細化による大規模化にともない、単に配線CADだけでは足りなくなっており、最適な配置配線の計算やシミュレーション、物理的な信号シミュレーション、タイミングシミュレーションなど、さまざまな機能を提供している。
EDAツールだけでなくIPも提供しており、LSIの企画から製造の手前(つまりテープアウトした設計を工場に納入する直前)までの範囲のソリューションを提供している。これはCadenceも同じことで、いわば設計に関するワンストップサービスを両社とも提供している格好だ。
もちろんその分お値段もすさまじい。昨今の先端LSIの設計コストが高騰している一因は、このEDAツールの利用料の高さにある。もっとも「EDAツールが高すぎるから一切使わずに人手だけでなんとかするわ」が通用するのはせいぜい500nmあたりまで。7nmや5nm世代を人手だけで設計したら、間違いなく完成しない。もうこれは必要経費と割り切って、LSIを作りたかったらまずEDAツールの利用代をかき集めるところから始める必要がある。
話が逸れたが、SynopsysはさまざまなIPを提供しているが、これらは自社開発というよりはIPを持っている会社を買収してラインナップに加えたものが圧倒的に多い。今回説明するARC NPUもその1つである。
(*1) 昔はこれにMentor Graphicsを含めた3大EDAベンダーが存在したが、Mentor Graphicsはやや遅れをとり、さらにその後Siemensに買収されて現在はSiemens EDAに改称されている。
ARC Internationalの前身は、名作「スターフォックス」を 任天堂と共同開発したArgonaut
Synopsysは2010年にARC International LTDを買収するが、このARC International、もともとはArgonaut Gamesというビデオゲームの開発会社だった。「ゲームの開発会社」といっても単にゲームソフトの開発だけでなく、ハードウェアの開発も手掛けていたのがおもしろいところだ。
同社の最初のゲームはCommodore 64向けのSkyline Attack(1984年)で、次いでAmiga ST向けのStarglider/Sterglider 2(1986/1988年)という具合にコンスタントにゲーム機向けのタイトルを発売していくが、これと並行してハードウェアの開発も手掛けることになった。
元はと言えば、Starglider/Sterglider 2のNES(ファミコンの海外仕様)版の企画を任天堂に持ち込み、これがSNES(スーパーファミコン)向けゲームタイトルとして採用されることになった。
ただしスーパーファミコンがその時点で想定していたハードウェアでは、Starglider/Starglider2のプレイには性能が足りず、そこでROMカセットの中に描画用ハードウェアを組み込むことにした。Super FXとして知られるこの追加のハードウェアは、こうして任天堂とArgonaut Gamesが共同開発することになった。

このSuper FXチップ、3Dポリゴンのレンダリングが可能な仕組みになっており、これを実装するためにArgonaut GamesはGPUアクセラレーター的に利用できる独自のRISCプロセッサーを開発する。このRISCチップをSuper FX専用にするのではなく、もっと他に販売できるのではないか? と思いついたことで、ARC Internationalが生まれることになる。
1995年、Argonaut GamesはATL(Argonaut Technologies Limited)という子会社を作り、ここにRISCプロセッサーなどのプロジェクトをまとめる(ゲームソフト部門はASL:Argonaut Software Limitedに集約された)。1996年にATLは完全分社化され、さらにその後ファンドの資金を得てATLは完全に独立、社名もARC Internationalに改称された。ちなみにARCは“Argonaut RISC Core”の略だそうだ。
安価でカスタマイズも可能なRISCプロセッサーARCシリーズ
ARC Internationalが最初にリリースしたのがARCtangent(明らかにArcとTangentを掛けたギャグだと思う)という32bitのRISC/DSP混載コア(フロントエンドは通常のRISCプロセッサーだが、バックエンドにDSP処理ユニットが搭載可能)であり、2003年にはARC600という次世代コアも発表している。

価格も安く、また構成を自由に変えられる(命令セットに手を入れることも可能)というあたりもあって評判は良く、わりと広範に使われていたARCコアであり、2005年に発表された後継のARC 700シリーズはARM11(ARM 1136J-S)に負けない性能を、より少ないエリアサイズと消費電力で実現できるとしていた。
ただこれに続くコアを開発中の2009年、同社はVirage Logicに買収される。Virage LogicはさまざまなIPを提供するベンダーで、同社のIPポートフォリオ充実のためにARCのIPは最適という判断だったのだろうが、そのVirage Logic自身が2010年にSynopsysに買収されたことで、ARCコアはSynopsysの手に渡ることになった。
といってもSynopsys傘下でも引き続きCPU/DSPコアのIPを提供していることに変わりはない。2020年にはARCv3と呼ばれる新しい命令セットを発表、64bit化が行なわれることになった。
余談であるが、Cadenceも同様にTensilicaというプロセッサーIPのベンダーを2013年に買収しており、こちらもProcessor/DSP IPとして現在も広く提供されている。
さて話を戻すと、このSynopsys傘下でもいろいろなところで同社のコアは利用されている。例えば連載706回でTenstorrentのWormholeをご紹介したが、内部構造のスライドで左側に“4core OoO ARC CPU, runs linux”とあるのがわかる。

おそらくはARC HS6xあたりが採用されているものと考えられる。古い話では、インテルが2015年に発表(して2017年には販売終了に)したCurieというチップがあるが、あれにはP5コアに加えて32bit ARCコアが搭載されており、MCUの機能はこのARCコアが担っていた。
ほかにも、WD(Western Digital)が最近はHDDのコントローラーを自社設計のRISC-Vベースに切り替えつつあるが、その前はARCプロセッサーのライセンスを受けて利用していた。要するに直接表に出てこない制御用プロセッサーとして、ARCコアは非常に広範に使われているわけだ。
Synopsysが提供しているプロセッサーIPのラインナップは下表のとおり。
このラインナップであっても、AI需要の高まりに向けて、ARC VPXをベースに機械学習のネットワークを稼働させるためのライブラリーを提供したり、より機械学習の性能が必要なエンベデッド・ビジョン(組み込み機器)向けにはARC EVを用意したりしていたのだが、より広範な用途にAIが応用され始める気配が見えてきたことから、これに向けてより強力な性能のプロセッサーIPを提供することにした。
それが2022年に発表されたARC NPXファミリーである。現状はNPX6とNPX6FSの2つがあるが、NPX6FSは車載向けに機能安全対応用の機能が追加されただけで、NPUとしての性能はNPX6とまったく違いがない。
さて、「一般的」というだけあって、わりとどんな用途でもそれなりの性能が出せるようにということで、構成はすさまじい。各々のコアは4096個のMACエンジンが搭載され、これで畳み込み処理を行なう。
それとは別に、ネットワークにまつわる処理(アクティベーションやプーリングなど)はTensor Acceleratorと呼ばれる専用の回路が実施する。またMACエンジンはデフォルトではINT 4/8/16にのみ対応するが、オプションでBF16/FP16にも対応する。このBF16/FP16を利用するには、ライセンス利用扱いになっているTensor FPUを追加する格好だ。

個々のコアはL1メモリーを搭載(サイズは未発表)するが、これとは別に共有L2メモリーを最大64MBまで搭載可能である。コアそのものも最大24コアまで搭載可能で、最大構成では実に9万8304個のMAC演算を1サイクルで実施可能となっている。
後で出てくる性能比較ではTSMC N7でのケースだが、一応想定としてはTSMC N5かそれ以下のプロセスを考えているようで、このTSMC N5ではワーストケースでも1.3GHz動作が可能、最大構成での性能は440TOPSにおよぶ。
ちなみにこの440TOPSという数字はSparsityへの対応をTensor Acceleratorで行なった場合で、これをやらないと250TOPどまりだが、それでも結構な性能である。さらにこの24コアのNPUを最大8つ(これをオンチップでやるかオフチップでやるかは全体の設計次第)まで同時に接続可能で、ピークでは3500TOPS(Sparsityなしなら2000TOPS)という化け物で、もうAIトレーニング向けのチップ並みの性能を出せる、としている。
もっとも現実問題としては、64MBものSRAMを実装するとそれなりにダイサイズを喰うことになる。TSMC N5を使うRyzen 7000シリーズのL3が32MBで35mm2くらいなので、64MBでは70mm2に達するわけで、これを8つ実装するとそれだけで560mm2で、モノリシックなダイにするのは無理がある(NPU自身の面積を無視して、L2だけでこのサイズだからだ)。
またNPUはともかくL2をN5で実装するのは効率が悪いわけで、本当にやるならL2はそれこそ3D積層にして、N7かなにかのプロセスにしたいところだろうが、そうした構成はNPX6のままでは都合が悪い。個人的には、仮にNPX6を使って大規模なチップを作るとしたら、L2は最小限に抑えた構成とし、NPX6の外側に大容量のL3コントローラーを接続、そこに3D積層の形でL3メモリーを実装する方が現実的に思える。
もしくは、8つのNPUを同じダイにするのではなく、それぞれ別のダイとして製造の上でチップレット的につなぐ格好だろうか?
ちなみにSynopsysはチップレット用のI/F IPも当然提供しているので、こちらの実装はそう難しくはないだろう(それを言えば、同社は2020年から3DICコンパイラを提供しているので、3D実装もやはり同社のEDAツールを使う限りは相対的に容易だとは思うが)。
性能/消費電力比はJetson AGX Xavierのほぼ70倍
話が逸れたので元に戻すと、NPX6はさまざまなネットワークを利用することが前提なので、なるべく柔軟性を保つように工夫されている。

もちろんこれはハードウェアだけでは実現は難しく、Synopsysが提供するMetaWare MX Development Toolkitと呼ばれるソフトウェアと併用することで可能になっているわけだが。この中にはニューラルネットワーク向けのSDKも含まれており、既存のフレームワークをTOCA向けに変換するコンパイラと、それをVPXなりNPXなりで動かすためのランタイムが含まれている。
では実際にどの程度の性能が出るのか? ということで、同社のEV7xで動かしていたネットワークをNPX6に持ってきたときの性能を示したのが下の画像だ。
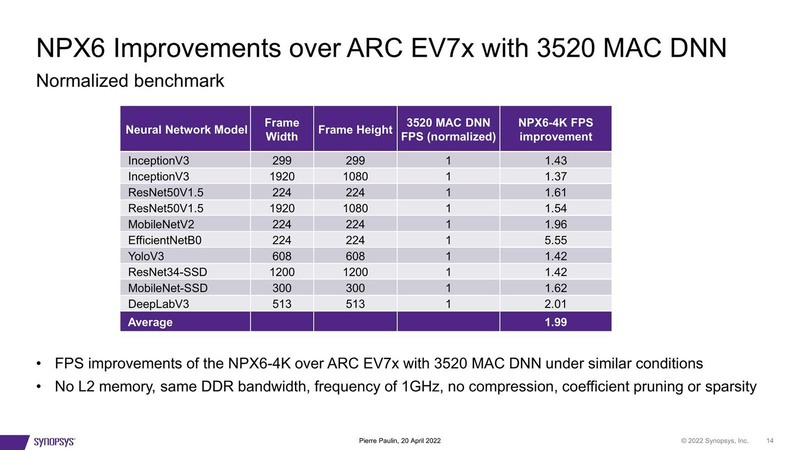
EV7は3520MAC、NPX6は4090MACの構成で、どちらも1GHz駆動、L2なしという状況で比較したものだが、おおむね2倍の性能となっている。ただこれでは性能がわかりずらいので、他社のAIチップと比較したのが下の画像だ。
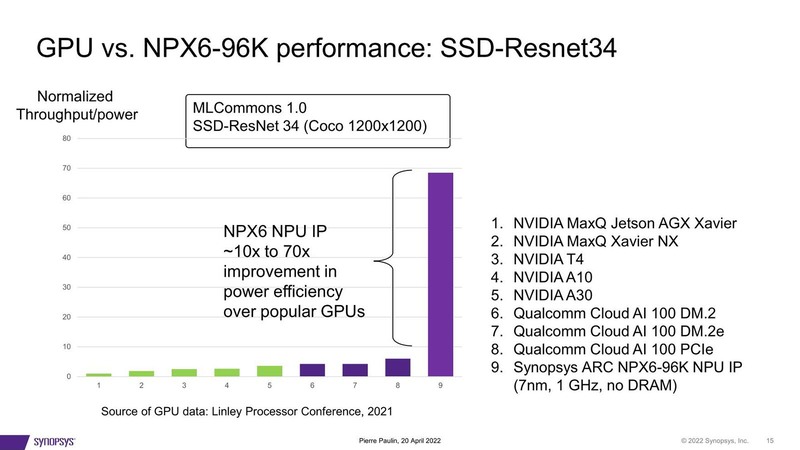
こちらは96K、つまりNPX6の最大構成の場合で、7nmプロセスで1GHz駆動にした場合のシミュレーションデータであるが、NVIDIAのGPUやQualcommのCloud AI 100と比較しても、圧倒的な性能/消費電力比(NVIDIAのJetson AGX Xavierのほぼ70倍)を実現できる、としている。
SynopsysはあくまでもIPを売る立場なので、これを半導体ベンダーが入手して自社製品に組み込む形で世の中に出るわけで、今のところ明示的にこれを採用した例というのは筆者は聞いたことがない。2022年に発表されたIPなので、早くても今年中に出れば御の字で、実際は登場しても来年以降だろう。
要求される性能にあわせて構成を変更できる、というのが利点ではあるのだが、やや性能とダイサイズのトレードオフが厳しそうな感じに見えるのは筆者だけだろうか? ただ先ほども書いたがチップレットなり3D構造なりにすればこのあたりは緩和されるので、それなりに性能が必要となる自動車の自動運転向けなどに、あるいは今後採用例が紹介されるかもしれない。

この記事に関連するニュース
-
VLSIシンポジウム2024プレビュー 第6回 プロセッサ/AI半導体/メモリアーキテクチャ分野の注目論文
マイナビニュース / 2024年5月15日 6時40分
-
M4チップ登場! 初代iPad Proの10倍、前世代比でも最大4倍速くなったApple Silicon
ITmedia PC USER / 2024年5月8日 1時0分
-
「Apple M4」チップ発表 - iPad Proが初搭載、第2世代TSMC 3nmプロセス製造
マイナビニュース / 2024年5月8日 0時8分
-
dynabook R9レビュー - 最新のCore Ultraプロセッサを搭載した「AI PC」の存在意義を考える
マイナビニュース / 2024年5月6日 6時0分
-
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ
ASCII.jp / 2024年4月22日 12時0分
ランキング
-
1ノリノリの音楽とともに敵を殲滅!リズムゲー要素ありなローグライクシューティングは日本語にも対応―採れたて!本日のSteam注目ゲーム8選【2024年5月16日】
Game*Spark / 2024年5月16日 22時0分
-
2小室哲哉も視聴済み 「Get Wildだと思ったらにんげんていいなだった」が約20万再生の人気で「このセンスほんと好き」「最高www」
ねとらぼ / 2024年5月16日 20時30分
-
3鋭すぎて取り扱い注意! 日本では珍しい先端0.1mmのテストリードが1400円
ASCII.jp / 2024年5月16日 10時0分
-
4「あて所に尋ねあたりません」 日本郵便の“404エラーページ”がおしゃれと話題 「センスいい」「遊び心よ」
ねとらぼ / 2024年5月16日 16時0分
-
5室内外機が一体化!2~3.7帖まで強力に冷やせるポータブルエアコン「BougeRV 1100W/4000BTU」
IGNITE / 2024年5月17日 10時26分
記事ミッション中・・・
記事にリアクションする
![]()
記事ミッション中・・・
記事にリアクションする

エラーが発生しました
ページを再読み込みして
ください





