

LLMによる視覚読解技術を確立 ~グラフィカルな文書を理解する「tsuzumi」実現に向けて~
Digital PR Platform / 2024年4月12日 0時0分
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)は、大規模言語モデル(LLM)によって文書を視覚情報も含めて理解する視覚読解技術を実現しました。実験において、文書画像を提示しながら、あらゆる質問への回答を行う人工知能(AI)の実現への可能性を示唆する結果が得られており、デジタルトランスフォーメーション(DX)におけるコア技術として期待されます。
なお、本成果はNTT版大規模言語モデル「tsuzumi※1」のアダプタ技術として採用・導入されております。本成果は、LLMベースの視覚文書読解に関する具体的な方法論を示した世界初の論文として、2024年2月20日~2月27日にカナダ・バンクーバーで開催されたAI分野における最高峰の国際会議であるThe 38th Annual AAAI Conference on Artificial Intelligence※2 (AAAI2024、採択率23.8%) において発表されました。また、2024年3月11日~3月15日に日本・神戸で開催された国内最大規模の自然言語処理に関する研究を扱う会議である自然言語処理学会第30回年次大会※3(NLP2024)にて、優秀賞(投稿論文中 上位2%)を受賞しました。
1.背景
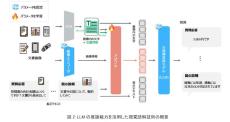
我々が扱う文書はテキストや視覚要素(アイコンや図表など)を含み、多様な種類・形式が存在します。こうした実世界の文書を読解し理解する技術の実現は、AI分野における重要課題の一つです。一方で、LLMを始めとする現在のAIは、人間の読解能力を超えるなど大きく発展してきましたが、文書中のテキスト情報しか理解できない限界がありました。この問題に対して、NTTではヒトの情報理解と同様に、文書を視覚情報から理解する技術として、図1で示す「視覚読解技術※4」を提唱し、本技術の実現をめざして研究開発を進めております。
[画像1]https://digitalpr.jp/simg/2341/86559/700_310_202404111010076617386fbc45e.JPG
2. 研究の課題
これまでの視覚読解技術は任意のタスク(例えば、請求書に関する情報抽出タスク)に対して対応することができませんでした。目的のタスクごとに一定数のサンプルを用意して学習を行わない限り、所望のタスクで高い性能を出すことは難しい状況でした。そこで本研究は、汎用な言語理解・生成能力を持つLLMをベースとして、任意のタスク用の学習を行わなくても応答できる、高い指示遂行能力を視覚読解モデルで実現することを目指しました。具体的には、テキスト情報しか理解することができないLLMに対して、どのように文書画像に含まれる図表などの視覚情報をテキストと融合させてLLMに理解させるか、が本研究で解決を目指した課題となります。

この記事に関連するニュース
-
データ分析の適用範囲を広げるバラバラなデータの回帰分析を世界で初めて実現 ~「万能近似能力」を持つ深層学習によるデータ分析の適用領域の拡大~
Digital PR Platform / 2024年4月26日 15時0分
-
目先のことを過大評価してしまう人間の行動を分析し最適な介入を導出する数理モデルを開発 ~シミュレーション実験の計算コストをかけずに、個人の目標達成の成功を支援~
Digital PR Platform / 2024年4月19日 15時7分
-
NTTがLLMで文書画像を視覚的に読解する技術を開発 - tsuzumiに搭載し展開も
マイナビニュース / 2024年4月12日 12時14分
-
AIが図表読み取り文章に要約 NTT、企業向け新技術
共同通信 / 2024年4月12日 0時2分
-
大規模データ間の類似度や対応関係を高速/高精度に算出する技術を開発 ~データの関係性を「素早く正確に測る」ことで、生成AIやメディア情報処理の革新的効率化を可能に~
Digital PR Platform / 2024年4月5日 15時5分
ランキング
-
1『100円ショップ』が円安で悲鳴「きついを通り越してどうしたらいいんだって感じ」利益を出すために「もう100円ショップじゃなくなるような…」
MBSニュース / 2024年4月30日 17時45分
-
2手取り30万円・40歳の新婚男性「後悔しています」「老後資金を考える余裕はない」強い不安のワケ
THE GOLD ONLINE(ゴールドオンライン) / 2024年4月30日 20時0分
-
3メニューたった3種類で急成長「鰻の成瀬」 東京チカラめし、いきなり!ステーキを反面教師にできるか
ITmedia ビジネスオンライン / 2024年4月29日 6時15分
-
4今後の為替相場は…“介入でも円安の流れを変えるのは難しい”見方広がる
日テレNEWS NNN / 2024年4月30日 22時15分
-
5激減した「サブウェイ」じわり復活している事情 意外と知られていない「パンへのこだわり」
東洋経済オンライン / 2024年4月27日 13時20分
複数ページをまたぐ記事です
記事の最終ページでミッション達成してください





